Volumetric and Multi-View CNNs for Object Classification on 3D Data
Stanford University
CVPR 2016
Abstract
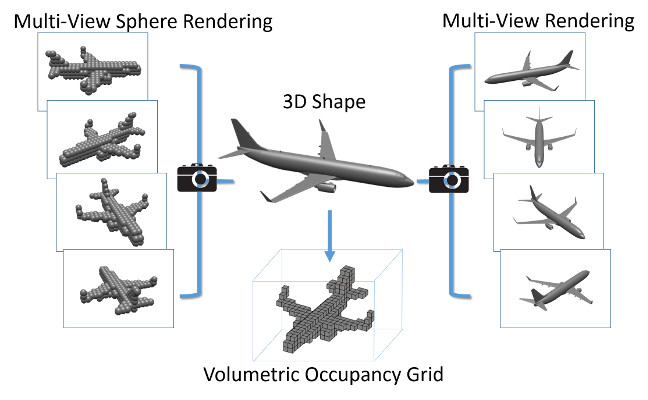
3D shape models are becoming widely available and easier to capture, making available 3D information crucial for progress in object classification. Current state-of-the-art methods rely on CNNs to address this problem. Recently, we witness two types of CNNs being developed: CNNs based upon volumetric representations versus CNNs based upon multi-view representations. Empirical results from these two types of CNNs exhibit a large gap, indicating that existing volumetric CNN architectures and approaches are unable to fully exploit the power of 3D representations. In this paper, we aim to improve both volumetric CNNs and multi-view CNNs according to extensive analysis of existing approaches. To this end, we introduce two distinct network architectures of volumetric CNNs. In addition, we examine multi-view CNNs, where we introduce multi-resolution filtering in 3D. Overall, we are able to outperform current state-of-the-art methods for both volumetric CNNs and multi-view CNNs. We provide extensive experiments designed to evaluate underlying design choices, thus providing a better understanding of the space of methods available for object classification on 3D data.
Paper | Dataset | BibTeX citation | Code | Slides
We provide a dataset containing RGB-D data and mesh reconstructions of 243 objects from 12 categories, for the purpose of 3D shape classification. The RGB-D data contains sequences taken from a PrimeSense sensor. Each sequence contains color and depth images, along with the camera intrinsics. Camera trajectories are provided per-object. Additionally, we provide meshes extracted from the reconstructions of this data (with objects segmented from the background). Please refer to the respective publication when using this data.
Format
Object meshes: .obj meshes of the objects by category.Raw scan data: We provide 208 sequences of tracked RGB-D camera frames, from which the 243 objects were extracted. We use the VoxelHashing framework for camera tracking and reconstruction. Each sequence contains:
- Color frames (frame-XXXXXX.color.jpg): RGB, 24-bit, JPG
- Depth frames (frame-XXXXXX.depth.png): depth (mm), 16-bit, PNG (invalid depth is set to 0)
- Camera poses (frame-XXXXXX.pose.txt): camera-to-world
- Camera calibration (info.txt): color and depth camera intrinsics and extrinsics. Note that these are the default intrinsics and we did not perform any calibration.
mapping.txt: Since mulitple objects may be extracted from a single scanned sequence, this file contains a mapping from each object to its original scan data.
License
The data has been released under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 License.