Technical Report CSRP-98-13
School of Computer Science, The University of Birmingham
GP-Music: An Interactive Genetic Programming System for Music Generation with Automated Fitness Raters
|
Brad Johanson Stanford University Rains Apt. 9A 704 Campus Dr. Stanford, CA. 94305 650-497-7543 |
Riccardo Poli University of Birmingham School of Computer Science The University of Birmingham Birmingham B15 2TT +44-121-414-3739 |
Abstract
In this paper we present the GP-Music System, an interactive system which allows users to evolve short musical sequences using interactive genetic programming, and its extensions aimed at making the system fully automated. The basic GP-system works by using a genetic programming algorithm, a small set of functions for creating musical sequences, and a user interface which allows the user to rate individual sequences. With this user interactive technique it was possible to generate pleasant tunes over runs of 20 individuals over 10 generations. As the user is the bottleneck in interactive systems, the system takes rating data from a users run and uses it to train a neural network based automatic rater, or "auto rater", which can replace the user in bigger runs. Using this auto rater we were able to make runs of up to 50 generations with 500 individuals per generation. The best of run pieces generated by the auto raters were pleasant but were not, in general, as nice as those generated in user interactive runs.
1 Introduction
Since the first computers were available, people have been using them to create and compose music. In the past twenty years there have also been programming languages created for music composition, and in the past ten years some researchers have tried to apply genetic algorithms, sometimes with neural networks as automatic raters, to the task of composing and creating music. Only one approach based on GP has been presented. We describe previous work in this area in Section 2.
In this paper we present the GP-Music System, an interactive system which allows users to evolve short musical sequences using interactive genetic programming, and its extensions aimed at making the system fully automated. The basic GP-system works by using GP with a small set of functions for creating musical sequences, and a user interface which allows the user to rate individual sequences.
A key feature of the GP-Music System is its focus on using Genetic Programming instead of Genetic Algorithms. Since GAs use fixed length genotypes to represent a problem, in this case a musical sequence, they are forced to a fixed length, and cannot easily apply functions to add structure to a sequence. With Genetic Programming it is possible to add functions so that simple musical structures, such as phrase repetition, are available within the individuals being evolved. GP also has the advantage of allowing variable length sequences to be generated.
Another important aspect of the GP-Music System is that it is focused on creating short melodic sequences. It does not attempt to evolve polyphony or the actual wave forms of the instruments. Only a set of notes and pauses is created by the system. This narrow focus allows a reasonable musical sequence to be generated by a user during runs that last about 10 minutes and require a relatively small number of evaluations. The interactive GP-Music System is described in Section 3.
The basic system, with a user serving as the fitness function, has shown that it is possible to evolve musical sequences with genetic programming and achieve reasonable sounding melodies as a result. One main problem with the system, however, is that the user must listen to and rate each musical sequence in every generation during a run. For long tunes this may be a long and (at least initially) tedious process requiring hours to complete even with small populations and short runs. Also, it is arguable that for the evolution process to work properly in this difficult domain large populations over tens to hundreds of generations might be needed, which is entirely impractical with a human having to rate each sequence.
To alleviate this problem, we extended GP-Music creating automatic fitness raters which could stand in for the user in rating sequences. The user would rate a small number of sequences in a short run on the GP-Music System, and the automatic rater would use the resulting ratings to learn to rate sequences in a similar fashion. The automatic rater could then stand in for the user in longer runs of the system. To this end, an automatic rater, or auto-rater was constructed which is based on a neural network trained using back propagation. Auto-raters are described in Section 4.
Experimental results with the GP-Music system with and without auto-raters are described in Section 5. We draw some conclusions and indicate directions for future work in Section 6.
AI based attempts at music composition are Cope's EMI [2] and Todd's Connectionist Approach [9]. Cope created an expert system which was attuned to his own style of composition and was able to use it to create perturbations of a theme for use throughout a larger composition. Todd worked on a neural network which was trained on pieces in the hope that it would extract some ideas of important features in music. Using a feedback system, the network is able to continue a composition based on previous notes.
Several attempts have also been made to apply Genetic Algorithms and Genetic Programming to music composition. Spector and Alpern [8] came up with a GP system which evolved responses to call phrases in jazz pieces. As a fitness function they used a neural network trained on real responses from known jazz pieces, and tried to get the system to generate good responses. Unfortunately it was not very successful since the neural network did not have an adequate amount of training on poor responses. Biles [1] designed the GenJam system which uses Genetic Algorithms. It evolves measures, and phrases (which are a series of measures) simultaneously in a real time fashion. As the user listens to a stream of phrases and measures, they type `b' for bad or `g' for good. The accumulation of `g's and `b's serves as the fitness for the measures. This is interactive GA, and the author reports that although some decent phrases eventually begin to emerge, the process is tedious. Another system using GAs is Neurogen [3]. It used a three stage approach where rhythm is first created, and then added in with melody, and finally combined with other phrases to create a harmony. Short GA strings are evolved for each of these stages, and a neural net is trained on existing musical pieces, then used to rate the strings for the GA process. The authors report that initial results are promising, but do not present any derived music.
The GP-Music SystemThis section outlines the main features of the GP-Music System which allows users to interactively evolve music. The system uses a modified version of the lil-gp GP system [10]. The rest of this section describes the features of GP-Music that allow it to apply genetic programming to the task of music composition.
3.1 Music Sequences
Rather than designing a new file format for storing the melodies created by GP-Music, an existing music file format was chosen¾ the XM, or extended module format. XM files store musical pieces rather than straight digital audio. In other words, note sequences are stored and then synthesized at play time, rather than storing a recording of the music. The XM format stores digital samples of the instruments to be used in playing each of the notes, and can thus be played on any workstation with digital audio output capabilities.
One of the features of Genetic Programming is that it can achieve good results without the need to apply a lot of domain knowledge in the specification of the problem. One of the objectives of the project was to explore this idea. So, we decided not to constrain the search of GP Music to an arbitrary subset of music theory, but instead used the basic note features available in the XM format to determine the general structure of what was being evolved. Specifically, the XM file allows a basic pattern size of up to 255 note events (only one pattern is used in the GP-Music System). Each note event can contain either a note to be played, or a rest command. The notes themselves come from the standard scale and include: C, C Sharp, D, D Sharp, E, F, F Sharp, G, G Sharp, A, A Sharp and B. The notes fall over eight octaves, and the notation for this is to append the octave number, from 0 to 7, after the note. Thus, a fourth octave D Sharp is noted as D#4. A single channel of melodic piano is used, with one pattern of 255 time slots. Each of the beats can be either a note or a rest (RST). The notes fall in the range of C-0, C#0, D-0, up to G#5, A-6, A#6, and B-6.
3.2 Function and Terminal Sets Description
The terminal and function sets for the GP-Music System are the notes which are used in the created melodies, and a small collection of routines to modify note sequences. They are summarized in Table 1, and are subsequently explained in more detail.
|
Function Set: |
play_two, add_space, play_twice, shift_up, shift_down, mirror, play_and_mirror |
|
|
Terminal Set: |
Notes: |
C-4, C#4, D-4, D#4, E-4, F-4, F#4, G-4, G#4, A-5, A#5, B-5 |
|
Pseudo-Chords: |
C-Chord, D-Chord, E-Chord, F-Chord, G-Chord, A-Chord, B-Chord |
|
|
Other: |
RST |
|
Table 1- The Terminal and Function Sets in the GP-Music System
The Terminal Set
The terminal set used consists of notes in the 4th and 5th octaves available in the XM file format. The range of notes used was limited to one or two octaves (depending on the run) to prevent pieces with large pitch ranges from being too prevalent. In addition, the RST terminal is used which indicates one beat without a note.
Finally, there is a set of seven pseudo-chord terminals. Each of these is a sequence of three notes that follow the same pitch separation as a chord. They are denoted pseudo-chords since they are played sequentially instead of simultaneously. The exact notes used in each of the pseudo chords are listed in Table 2.
|
Pseudo-Chord |
Corresponding Note Sequence |
|
C-Chord |
C-4,E-4,G-4 |
|
D-Chord |
D-4,F#4,A-5 |
|
E-Chord |
E-4,G#4,B-5 |
|
F-Chord |
F-4,A-5,C-5 |
|
G-Chord |
G-4,B-5,D-5 |
|
A-Chord |
A-5,C#5,E-5 |
|
B-Chord |
B-5,D#5,F#5 |
Table 2- Pseudo-Chord Note Sequences
The Function Set
The routines in the function set all operate on one or more note sequences which are passed to them. They perform some transformation on the note sequence (or sequences), and then return a new sequence. They will now be discussed individually.
The functions in the set were chosen for various reasons. `Play-two' was included as a necessary function to allow sequences longer than one note. The other functions allow structured note sequences to become more common.
3.3 Interpreter
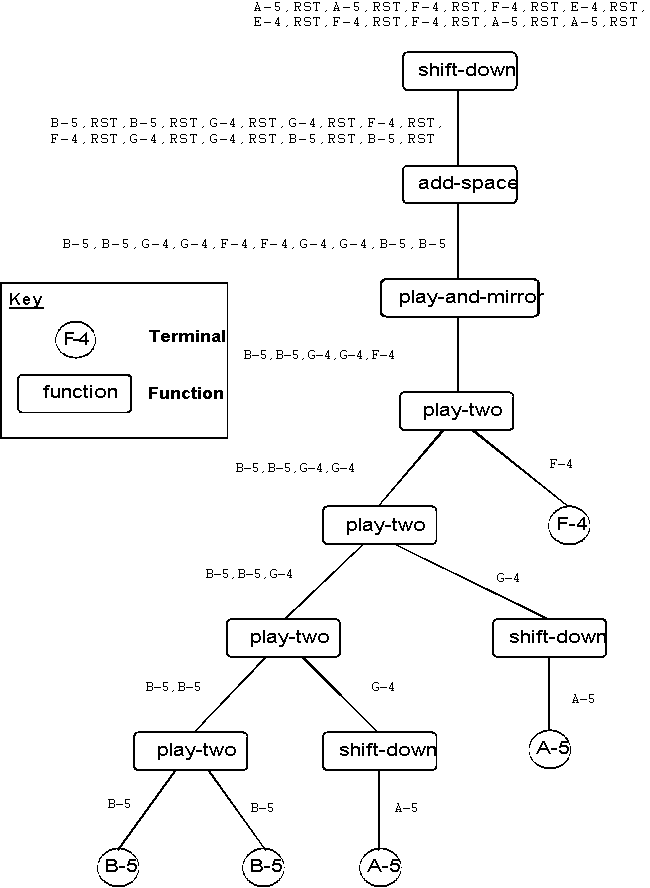
Unlike in many other GP examples, the item returned by the program tree in the GP-Music System is not a simple value. Instead, the program tree creates a note sequence. The programs created are typically printed in a LISP-like fashion, and look something like the program in Figure 1.
|
(shift-down (add-space (play-and-mirror (play-two (play-two (play-two (play-two B-5 B-5) (shift-down A-5)) (shift-down A-5)) F-4)))) |
Figure 1- Sample Music Program
When evaluated, the program in Figure 1 generates a string of notes. Each node in the tree propagates up a musical note string, which is then modified by the next higher node. In this way a complete sequence of notes is built up, and the final string is returned by the root node. Note also that unlike most of the programs created in GP applications, there is no input to the program; the tree itself specifies a complete musical sequence. Figure 2 shows how the note sequence is built up, using the program in Figure 1 as an example.
Figure 2- Example Music Program Tree Evaluation
The figure shows the note strings being passed up from each node. Also, note that the `shift-down' functions in the example shifts down to the next whole note. This is because the sequence in question was generated with a C-Major key feature turned on and only the seven whole notes are being used.
It is worth noting how this technique provides more flexibility than the GA approaches used by others in similar research (see Section 2) where fixed length sequences are evolved.
3.4 Fitness Selection and User Interface
Since the suitability or quality of a musical piece is largely subjective, it is not possible to use a strict mathematical function to assign a fitness to individual note sequences which are generated. Instead a human using the system is asked to rate the musical sequences that are created for each generation of the GP process. This is similar to Poli's [7] system for evolving pseudo-coloring algorithms.
The user rates the individual sequences using a simple ‘list’ style X-Windows interface. The principle of the list interface was to give the user all of the sequences in a generation in one big block which could be rated in any order that they chose. This allows the user to change their mind about a sequence's rating after they have heard what the `competing' sequences sound like. The user rates each musical sequence on a 1-100 scale. The user interface is shown in Figure 3.
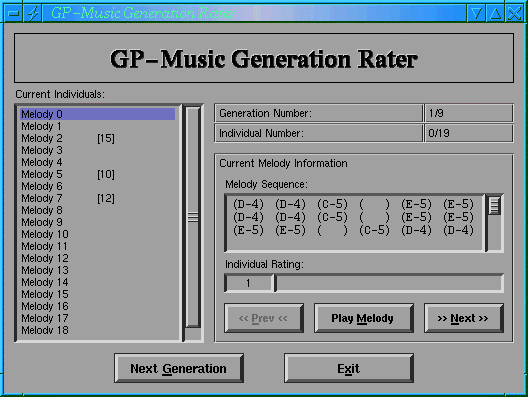
Figure 3- The GP-Music User Interface
3.5 Modifications to the Basic GP Algorithm
Two changes were made to the basic GP algorithm to better accommodate it to the interactive nature of the GP-Music System. The first was to force fitness ratings to be consistent from generation to generation, by insuring that identical sequences have the same fitness. The second was to automatically eliminate unsuitable sequences, such as single notes, in a given generation.
Enforced Inter-Generation Consistency
One of the problems with interactive GP applied to music is that ratings are subjective. The list interface helps the user to maintain a consistent rating scheme among sequences in a given generation, but not between generations. Since each generation was rated as a separate group, a user might always rate the best individual in a generation the same, despite the fact that overall the sequences were improving. One of the GP operators, however, is reproduction, where an individual is copied directly from the previous generation into the new one. If the copied sequence is presented to the user in a new generation it is quite likely to be rated differently from in the previous generation. To fix this problem, the system code was changed so that an individual's rating is locked in from generation to generation. The list interface also allows the user to listen to the previously rated piece and see its rating before rating the new generation. This helps them to mentally recalibrate for the new set of sequences.
Automatic Elimination of Unsuitable Individuals
One of the problems in early versions of the system was the creation of melodies that were so short or so long that they always garnered low ratings. Since the generation size is already small for user interactive genetic programming, having these unsuitable individuals in the population reduced the diversity and efficiency of the evolution process. The user can now choose a certain note sequence length minimum and maximum for a run, as well as a minimum and maximum number of notes. During the breeding phase of the genetic programming process, individuals that don't meet the criteria are automatically destroyed, and a new individual is bred and this process is repeated until a satisfactory individual is created. Using this method the user can devote their time to rating sequences with more potential. It also insures that the complete population size participates in the evolutionary process.
This section presents the architecture used to create the automatic fitness raters for the GP-Music System. Our automatic fitness raters are based on neural networks with shared weights and are trained with the back propagation algorithm. They give ratings on a 1-100 scale in a similar fashion to a human using the list interface described in Section 3.4.
In normal back propagation networks, each connection into a node has its own weight which is modified by the back propagation training. In a network with shared weights, however, some of the connections use the same weight, and the weight will therefore be modified several times during the back propagation, once for each connection with which it is associated. The use of shared weights allows the rating of sequences of variable length, which would be a very hard problem using standard neural network topologies. The details of how shared weights are used in this case will be explained along with the discussion of the network topology.
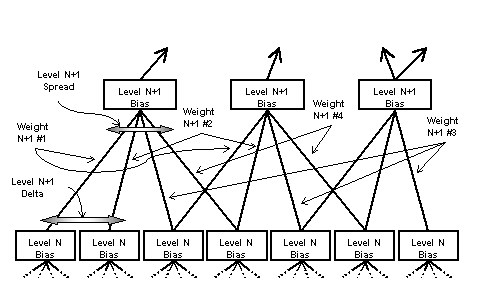
Figure 4- Basic Auto-Rater Network Layout
The basic unit of topology for the network is shown in Figure 4. The diagram shows two layers of an auto-rater network, and the connections between them. The bottom most level, labeled `Level N', is closest to the inputs (or possibly is the input layer), and the upper level, labeled `Level N+1', is closest to the output node, or nodes (or possibly is the output layer). Each node in the upper level receives input from the lower level nodes. The value of the parameter `Level Spread', in this case 4, determines how many nodes feed into one of the higher level nodes. The first node on a level receives input from the first `Level Spread' nodes of the next lower level. The second node receives input from subsequent nodes, possibly receiving some of its inputs from lower level nodes also feeding into the first node.
The `Level Delta' determines the amount of overlap between connections to adjacent nodes in the upper level. In the case of the diagram it is 2, meaning that the first node receives inputs starting with the first lower level node, while the second node receives input starting with the third lower level node. In the diagram, this means that each lower level node affects two upper level nodes. Setting the `Level Delta' to lower values increases the overlap, and the ability for the higher level to correlate among nodes in the lower level, while increasing it causes each upper level node to act in a more autonomous fashion.
As mentioned earlier, each of the top level nodes has `Level Spread' connections to lower nodes. The weights on these connections are all shared, so the weight on the first input to each upper level node is identical, and during back propagation the weights are modified according to the error coming back from each of the top level nodes. Note that the weights are used in a consistent sense with weight one always being used to connect the first lower level node to the upper level one (which also corresponds to connecting to a point earlier in the note sequence, as will be discussed below). The biases are also shared between all nodes on a given level, so in effect each node and its inputs are duplicate networks. The overall topology, shown in Figure 5, has five layers, including the input layer, and one output node.
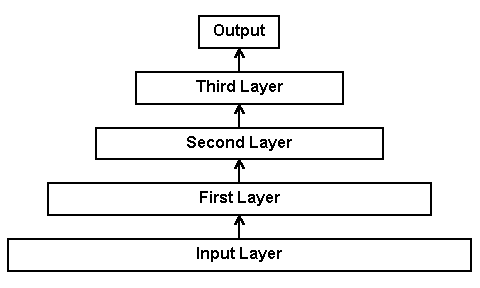
Figure 5- Global Topology for Auto Raters
Since the note sequences being rated are variable in length, a new network is built up for each individual that the network is required to evaluate or with which it is being trained. Consistency is maintained by storing the shared weights and biases and using them for each network that is built. The network is constructed by first creating one input node for each time slot in the sequence being evaluated. The value of the note at that point in the sequence is then loaded into the input node in the following manner:
Enough first layer nodes are then constructed to exactly match the number needed given the first level spread and delta amounts. For example, a sequence of length six, with a level one spread of four and a level one delta of two would need two nodes at the first layer. If the number of input nodes does not correspond to a whole numbered amount of first layer nodes, the amount used is rounded up (as is the case in Figure 4, for example). Once the nodes for the first level are created, the connections between the two levels are made as described above, using the shared weights for the first layer. The second and third layers are constructed in a similar fashion, and then each third layer node is connected to the output node of the network which outputs a value between 0 and 1. This is multiplied by 100 to create the appropriate rating on a 1-100 scale.
The construction of the network in this fashion allows it to telescope out to whatever the length of the input note sequence. Since the weights are the same going into each of the first layer nodes, each `level one spread' width sub-sequence is evaluated in a similar manner. At higher levels, the correlations of the sub-sequences from lower levels are being evaluated in similar manners.
The parameters that are available to be adjusted for the auto-rater are: Level 1 Spread, Level 1 Delta, Level 2 Spread, Level 2 Delta, Level 3 Spread and Level 3 Delta. Each of these can be modified to change how accurately the network is able to rate sequences in a training set.
This section documents the experimental work done with the GP-Music System and the auto raters. First several interactive runs and the resulting sequences are described, followed by a description of the results of training the auto rater, and, finally, a description of some runs using the auto rater instead of the user.
The basic parameters used for the experimental runs were similar to those suggested by Koza in [6]. Individuals were selected for reproduction using 4 individual tournament selection. The genetic operators were crossover, reproduction, and mutation with probabilities 0.7, 0.15 and 0.15, respectively. Six generations were used with a generation size of 16. Initial tree depths were limited to between 1 and 4 levels, with a global maximum depth of 6 levels.
5.1 User Interactive Runs
The first trial made was primarily to verify what the GP-Music System can generate using the minimal set of functions and terminals, so the parameters chosen were as simple as possible. The operators were 'play_two' and ‘add-space.’ The former allowed sequences longer than one note, and the latter variability in tempo. In addition, the notes were restricted to one octave, and no pseudo-chords were allowed.
The sequences generated during the base line runs tended to not have much structure, and many of the individuals sounded poor. One best of run individual is shown in Table 3.
|
Gen. |
Nodes |
Depth |
Seq. Len. |
Fitness |
|
3/5 |
28 |
6 |
26 |
40.00 |
|
Program Tree: |
||||
|
(play-two (play-two (add-space (play-two F-4 B-5)) (add-space (play-two B-5 F#4))) (play-two (add-space (play-two (add-space F#4) (play-two B-5 (play-two F#4 D#4)))) (play-two (add-space (add-space E-4)) (add-space (play-two F#4 D#4))))) |
||||
Web Site File Name: 2tune.au |
||||
Table 3- Base Line Trial Best of Run Individual
This particular individual sounds quite pleasant despite the fact that it was created using the simplest function set of all of the cases. It was found in the 4th generation, indicating that better pieces were being generated as time went by. This and the other sequences reported in the paper are available at http://www.cs.bham.ac.uk/~rmp/eebic/WSC2/gp-music/gp_music.html.
The next step beyond the Base Line trial was to add in the more complicated functions in the function set in Table 1. Although the pieces generated in the base line trial were not bad, most of them lacked structure. The sequences generated during this trial were better overall than those of the Base Line trial. Adding the new functions seemed to smooth out the variation between the best and worst individuals. Having the structure kept very bad individuals from appearing perhaps at the expense of less variety in the good individuals. An example best of run individual is shown in Table 4.
All Functionality
The next trial involved the addition to the terminal set of the pseudo-chords and the limitation of the notes to the C-Major scale. The motivation for the addition of pseudo-chords was to add some short sequences that were known to sound good into the program trees. In addition, the initial tree depths were set to 4 to 6 levels, and the maximum depth to 9 levels.
|
Gen. |
Nodes |
Depth |
Seq. Len. |
Fitness |
|
3/5 |
21 |
8 |
21 |
25.00 |
|
Program Tree: |
||||
|
(play-two (play-and-mirror B-5) (mirror (play-two (shift-up (play-two (mirror G-4) (play-and-mirror D-4))) (play-twice (play-two (play-twice F#4) (play-twice (play-two (shift-down A-5) (add-space F#4)))))))) |
||||
Web Site File Name: 4tune.au |
||||
Table 4- Complex Function Set Best of Run Individual
The effect of this trial was startling. Almost all of the generated individuals were pleasant to listen to. The only drawback is that some of the individuals sounded similar as they all tended to rely on the pseudo-chords. A typical best-of-run individual is shown in Table 5.
|
Gen. |
Nodes |
Depth |
Seq. Len. |
Fitness |
|
4/5 |
15 |
8 |
60 |
22.75 |
|
Program Tree: |
||||
|
(play-and-mirror (shift-down (play-two (play-and-mirror (shift-down (play-two (shift-up (add-space A-Chord)) (shift-up (add-space A-Chord))))) (shift-up (add-space A-Chord))))) |
||||
Web Site File Name: 9tune.au |
||||
Table 5- All Functionality Best of Run Individual
This sequence uses the structuring of the complex functions and the pseudo-chords to its advantage, playing the ‘A-Chord’ backwards and forwards with an interesting stutter in the middle.
Training Run
An additional, longer run, was made to gather data for use in training the auto rater. The training data was gathered by running the GP-Music System over 10 generations with 20 individuals per generation. This led to the rating of a total of two hundred individuals. The maximum depth allowed was also increased to 12. In all other respects the computer was configured as for the 'All Functionality' trial. The human rater was Anne Pearce, a retired music teacher. The best individual generated by the run is shown in Table 6.
|
Gen. |
Nodes |
Depth |
Seq. Len. |
Fitness |
|
9/9 |
24 |
9 |
120 |
46.00 |
|
Program Tree: |
||||
|
(play-twice (play-two (add-space (shift-up (play-two (play-twice (play-and-mirror (shift-down (shift-up D-Chord)))) (play-two (play-twice G-Chord) (mirror F-Chord))))) (play-and-mirror (shift-down (shift-up (play-two (play-twice G-Chord) (mirror F-Chord))))))) |
||||
Web Site File Name: anne-list-best.au |
||||
Table 6- Training Run Best Individual
This individual is quite nice, certainly longer, and perhaps superior to any of the others that we have generated. The tune sounds almost like some old sea shanty, although it ends quite abruptly. During this run the two hundred ratings and the associated sequences were captured for use to train the auto-rater.
5.2 Training the Auto Rater
The ratings generated during the human run were used to train the auto-rater network described in Section 4. The ratings were divided up into two sets of 100 individuals, one to serve as a training set and one to serve as a control set. For each training of the network, the individuals in the training set were repeatedly used to modify network weights and biases using back propagation. Statistics were kept during the training measuring the decimal error (the absolute value of the difference between the human and network rating on a 1-100 scale) for both the control and training sets. These measurements were made after each complete cycle through individuals in the training set. Statistics were also kept for the average decimal error for a given sequence length, and the fraction of individuals falling into any particular error range (the error distribution) for each training cycle.
The auto-rater network was trained over many combinations of the parameters listed at the end of Section 4 in order to find the optimum values for such parameters. The optimum values resulted to be: Level 1 Spread = 8, Level 1 Delta = 4, Level 2 Spread = 8, Level 2 Delta = 4, Level 3 Spread = 4 and Level 3 Delta = 2. These choices give 24 degrees of freedom—8 level one weights, 8 level two weights, 4 level three weights, and biases for levels one, two, three, and the output node.
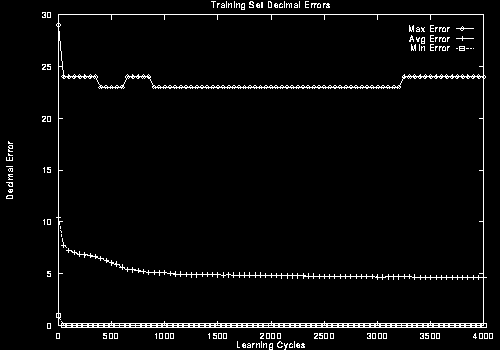
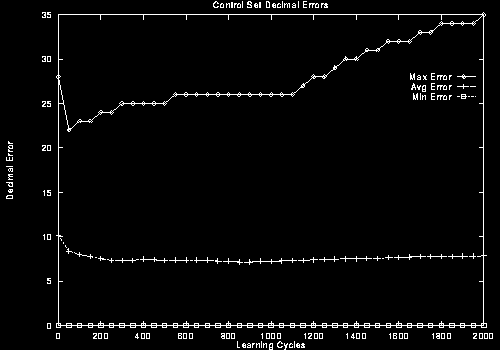
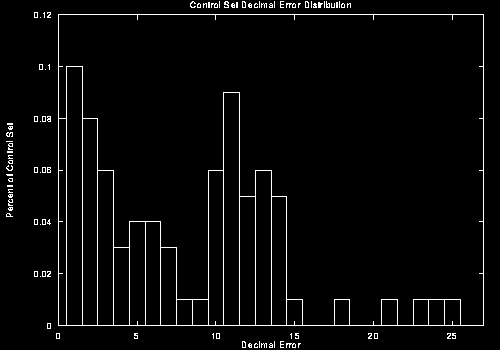
The decimal error rates are shown here in Figure 6. The maximum, minimum and average error for each training cycle is shown, for both the training and control sets.
The average error on the training set goes down to +/- 5, which is quite good when the rating is out of 100. Unfortunately, the maximum error is +/- 23 which is not so good. Of course the control set is more interesting, since the purpose of the rater is to evaluate individuals with which it has not been trained. Surprisingly, the error here is not much worse than the training set during the first 1000 learning cycles, suggesting that the tunes have a fair amount in common.
|
(a) Training Set |
(b) Control Set |
Figure 6- Decimal Error Rates
Inspection of the graph in Figure 6(b), and the data used to generate the graph, reveals that the average error on the control set reaches a minimum at cycle 850. This is the learning cycle at which training should stop to avoid overfitting. The minimum error on the control set is 7.16. This seems quite good on a 1-100 scale.
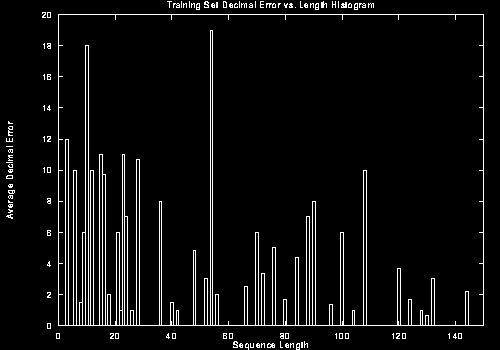
Since the maximum error at cycle 850 was still high, we also looked at what causes the error, one hypothesis being that the network might be quite good at rating certain sequence lengths and quite bad at others. To assess whether or not size was a factor in the error rate, length vs. average decimal error histograms are presented for cycle 850 in Figure 7.
As the figure shows, there is no clear correlation between sequence length and the average decimal error for a sequence. High errors are not clustered toward very long or very short sequences. There are some lengths that do have high error rates for both the training and control sets, but they don’t seem clustered in any particular way, and are probably due to the specifics of the internal structure of the particular sequences of that length.
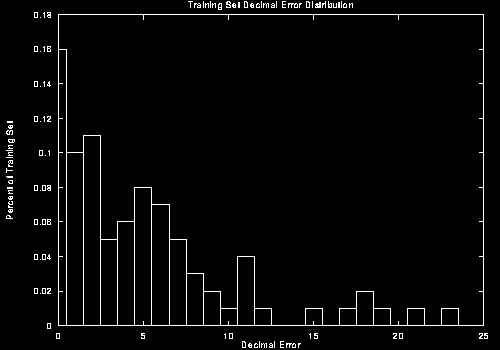
It is also important to look at the error distribution, since this shows whether most errors are very small with a few large errors that are bringing the average error rate up. Figure 8 shows the decimal error distribution for cycle 850.
|
(a) Training Set |
(b) Control Set |
Figure 7- Length vs. Decimal Error Histogram at Cycle 850
The error distribution for the training set seems to approximate a normal distribution quite well. The control set distribution seems to be bi-modal, with clusters around 0 and 12. Neither shows an extreme bi-modal distribution with most individuals at zero and one or two with large errors.
This analysis indicates that it is reasonable to train a network to rate sequences in the GP-Music System.
5.3 Auto Rater Runs
The weights and biases for the auto-rater network trained for 850 cycles were used in several runs of the GP-Music System. The first run was made with the same parameters used during the human run that generated the training set data. The best individual created is shown in Table 7. It was discovered in the seventh generation, indicating that evolutionary forces are coming into play. This individual actually sounds quite nice, although not as good as the one generated during the human generated run.
|
(a) Training Set |
(b) Control Set |
Figure 8- Error Distribution at Cycle 850
Of course, a run with 200 individuals is still feasible with a human user. The primary goal of using the automated rater is to complete runs with larger populations over a greater number of generations. To evaluate how well the auto-rater works in larger runs, runs with 100 and 500 sequences per generation over 50 generations were made. The resulting best individuals are shown in Table 8 and Table 9.
|
Gen. |
Nodes |
Depth |
Seq. Len. |
Fitness |
|
7/9 |
35 |
12 |
118 |
45.38 |
|
Program Tree: |
||||
|
(mirror (shift-up (play-two (shift-down (play-twice (play-twice (mirror (shift-up (play-two (play-and-mirror (play-and-mirror (add-space G-4))) (add-space F-Chord))))))) (shift-up (play-two (play-twice (play-twice (shift-up (play-two (play-and-mirror (play-and-mirror add-space G-4))) (add-space F-Chord))))) (shift-up (shift-down (mirror (mirror (play-twice (mirror (shift-up E2-Chord)))))))))))) |
||||
Web Site File Name: anne-200-best.au |
||||
Table 7- Auto Rater Best of Run Individual (10 Generations, 20 individuals per Generation)
Unfortunately, the sequence in Table 8 doesn’t sound nearly as good as the one generated during the smaller run. It alternates between low and high note sequences at the beginning, and then diverts into a different style at the end. A human would probably not have rated this piece so highly.
|
Gen. |
Nodes |
Depth |
Seq. Len. |
Fitness |
|
48/50 |
27 |
11 |
184 |
57.03 |
|
Program Tree: |
||||
|
(play-twice (mirror (play-two (add-space (add-space (add-space E2-Chord))) (play-twice (play-two (add-space E2-Chord) (play-two (add-space (play-two (add-space (mirror RST)) (play-and-mirror G1-Chord))) (mirror (mirror (play-twice (play-and-mirror (shift-down E2-Chord))))))))))) |
||||
Web Site File Name: anne-5000-best.au |
||||
Table 8- Auto Rater Best of Run Individual (50 Generations, 100 individuals per Generation)
The sequence in Table 9 is better than the previous one. It stays consistent during the length of the sequence, not changing pitch sequence or style. The sequence is quite strange, though, with only three different notes. Nonetheless, it is not unpleasant to listen to.
|
Gen. |
Nodes |
Depth |
Seq. Len. |
Fitness |
|
50/50 |
25 |
12 |
184 |
43.04 |
|
Program Tree: |
||||
|
(add-space (shift-up (shift-up (mirror (shift-up (play-two (play-twice (play-two (play-twice (play-twice (play-two E2-Chord RST))) (play-twice E2-Chord))) (mirror (play-and-mirror (add-space (play-two (mirror (add-space C2-Chord)) (play-twice (shift-up E2-Chord)))))))))))) |
||||
Web Site File Name: anne-25000-best.au |
||||
Table 9- Auto Rater Best of Run Individual (50 Generations, 500 individuals per Generation)
The three trials made show that the auto-rater on its own is able to evolve interesting, and pleasant sequences in the GP-Music System, but not in a consistent fashion.
Our work so far with the GP-Music System has shown that it is possible to evolve reasonable short melodies using interactive genetic programming. The improvement in quality between runs using only simple concatenation, and those using more complex structuring functions shows that GP has advantages over genetic algorithms for this type of task. Nonetheless, there is a user bottleneck problem whether GA or GP are used. A user can only rate a small number of sequences in a sitting, limiting the number of individuals and generations that can be used. We addressed this problem with auto raters, which learn to rate sequences in a similar fashion to the user, allowing longer runs to be made. These proved somewhat successful, but the auto rater runs were not able to generate nice sequences with the reliability of human rated runs.
Further work needs to be done to determine if the GP parameters, function and terminal sets that we have designed can be further optimized. The auto raters also need to be looked at in more detail. In particular it would be interesting to analyze the weights which are being learned by the network to see what sort of features it is looking for. It may also be possible to improve the structure of the auto raters themselves by feeding them extra information, or modifying their topology. In the short run it looks like runs with human-machine collaboration may be the best. The computer may be able to act as a first pass rater, allowing the human to rate only the best of the batch. Best individuals from computer runs may also be able to serve as members of the starting population for shorter human runs. Either way our research suggests that computers will be able to take a much more active role in computerized music composition in the future.
7 Acknowledgements
We wish to thank the members of the EEBIC Group at the University of Birmingham for their support. Special thanks are also deserved by Anne Pearce and Philip Underwood, who both participated in runs of the GP-Music System
Bibliography
Biles, J. A., "GenJam: A Genetic Algorithm for Generating Jazz Solos"