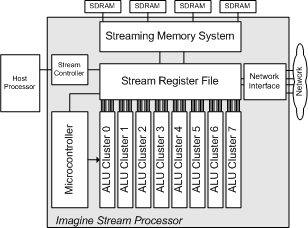
Here's a top level view of the Imagine architecture:
In the problem we're looking at, we begin with a stream of prepped triangles in the stream register file. The triangles are streamed through the ALU clusters, generating a stream of output pixels, which are written back to the SRF as they are produced. So all that's important for this problem is the stream register file, the microcontroller, and in particular the ALU clusters.
Note the clusters are all controlled by the same microcontroller in SIMD fashion. There are 8 clusters, so at any time, 8 triangles are processed at the same time.
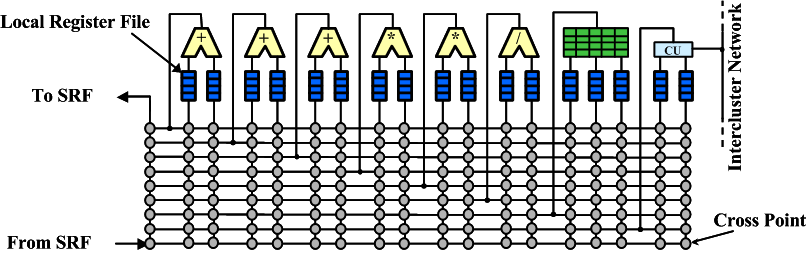
Each of the 8 clusters has 3 adders (which do both integer and floating-point adds, subtracts, and logical ops); 2 multipliers (both integer and floating point); and a divide/square root unit (both an integer and floating-point divide). There's also a scratchpad register file (256 entries - used for local array lookups) and a communication unit used for sending and receiving values to other clusters. Except for the divide/square root unit, each of these functional units is fully pipelined and can issue one operation per cycle.
Clusters are VLIW controlled with one important difference: instead of one giant register file feeding all functional units, each register file input is fed by its own private register file (usually 16 entries per RF). In this way we avoid the huge area, power, and delay cost associated with large multiported register files.
Instead, outputs of functional units must be switched through the cluster switch. Scheduling this switch is not a task which should be done by hand, so writing straight machine code for complex kernels is not tractable. Instead, we write them in C++ and allow a kernel scheduler to schedule the functional operations and the associated communications.