Machine Learning
Machine learning is a field of computer science that focuses on algorithms computers can use to understand and react to empirical data. Supervised learning is a very powerful application of machine learning that focuses on the specific problem of learning a function from a training set. A supervised leaning algorithm takes as input a set of training examples which contain the evaluation of the underlying function at a set of points, and after training on this data, can evaluate the function for any point in the domain. For example, a supervised learning algorithm might take as input the square footage of a house interior and the average value of houses in the city the house is located in, and predict the expected sale price of the house. This could be trained on an existing real-estate database and then used to predict the sale price for new houses. A supervised learning algorithm is called a classifier if the function output is discrete, and a regression function if the output is continuous. I first became interested in machine learning after taking and TAing CS/CNS/EE 156ab at Caltech and CS 229 at Stanford, both of which have excellent course notes on the subject.
In the course of taking classes and for my own research I have made my own supervised learning library in C++. Although you are free to browse the code to see C++ implementations of many of the most successful supervised learning applications, in general libraries such as WEKA contain much more optimized implementations and have almost every published supervised learning algorithm. This page mostly exists to show visualizations of many supervised learning algorithms on simple, easily visualized problems. This can help people gain an intuition of how the many parameters underlying these algorithms affect their behavior, and what the decision boundaries of the algorithms are. This can be useful when deciding which supervised learners will work best on a given problem, and what attributes might need to be tweaked to improve classifier performance.
Classifiers
Supervised learning classifiers can be largely categorized into binary classifiers, which can only disambiguate between two classes, and multiclass classifiers, which can disambiguate any number of classifiers. This distniction is important because some of the most powerful classification algorithms, such as support vector machines, map functions inputs to a single real number and separate the inputs into either the positive or negative class. To allow binary-only classification algorithms to operate on multiclass problems, meta-classifiers such as "One vs. All" have been developed that combine the results of many binary classifiers. Likewise, there are also meta-classifiers such as AdaBoost and bagging that combine the results of many "simple" classifiers together in the hopes of getting a classifier that has better overall performance than the individual classifiers. Below are brief descriptions of the classifiers I implement.
- k-nearest neighbor — Points in the space are classified by finding the k-nearest neighbors in the training set and returning the class distribution of these points. Typically, k is chosen to be odd to avoid ties.
- Decision tree — A decision tree classifies points by running them through a tree of simple decisions and looking at the training set's class distribution in the leaf node. Decisions might be of the form "is variable #3 greater than 0.5?". Decision trees are typically trained using something like the ID3 algorithm.
- Support vector machine — A support vector machine (SVM) is a binary classifier that finds the optimal separating hyperplane that partitions the domain such that points in different classes fall on different sides of the plane. The typical formulation of a support vector machine reduces to a quadratic programming optimization; my implementation uses sequential minimal optimization to efficiently find the best separating plane.
- Bagging and Boosting — These are meta-classifiers that combine the results of several "base" classifiers. Bagging is the simplest approach that simply averages the results of the base classifiers. Boosting is a general term used to characterize approaches that use a more complicated aggregation of the results of several base classifiers. In partictular, the AdaBoost algorithm has been used with great success. Typically the base classifier used is a very simple learner, such as a depth 1 decision tree (called a decision stump.)
- One vs. All and Pairwise Coupling — These are meta-classifiers that aggregate the results of many binary classifiers. One vs. all trains one binary classifier for each possible class, dividing classes into "X" and "not X". Pairwise coupling divides classes into a matrix of classifiers -- "X" vs. "Y" for all distinct classes X and Y. The final class probability distribution is typically aggregated by voting among the base binary classifiers.
Results
The results of the above learning algorithms on a simple 2D problem are shown below. In all cases the "real" decision boundaries can be described by simple functions. 400 points are randomly sampled and 300 are used for the training set, 100 for the test set. The results are then plotted showing the evaluation results of all points in the plane along with the test points. To see the effect of outliers on each learner, results are shown where 0%, 5%, and 15% of the data has been randomly assigned an incorrect classification. Of course, the results will look better as more samples are provided, but the behavior of the algorithms is most informative when only a small number of training points are used. Likewise, the relative behavior of the algorithms will change significantly with problem dimension and complexity -- but 2D problems are nice because they are so easily visualized.
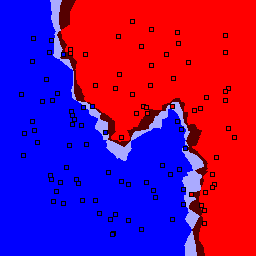
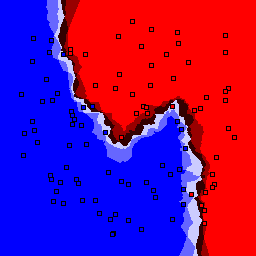
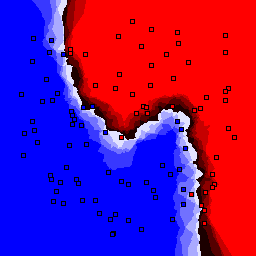
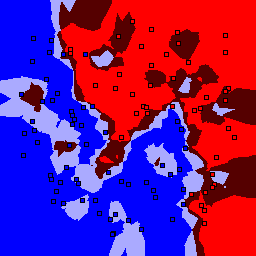
k-nearest neighbor
| k | 1 | 3 | 5 | 7 | 9 | 11 | 13 |
|
0% outliers Binary |

|
|
|

|
|

|

|
|
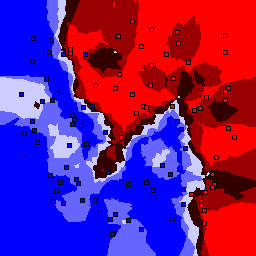
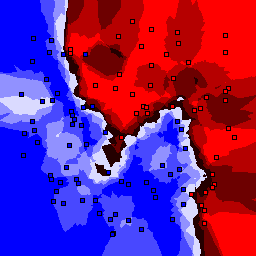
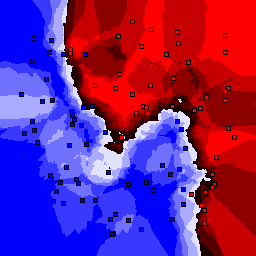
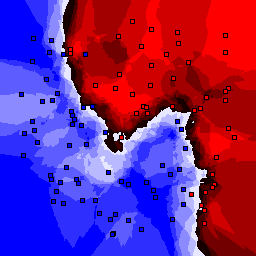
5% outliers Binary |

|
|
|
|
|
|
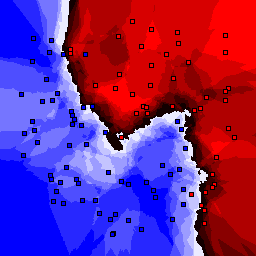
|
|
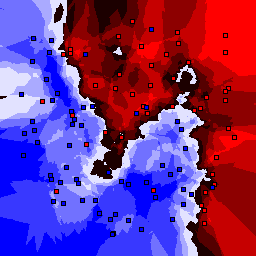
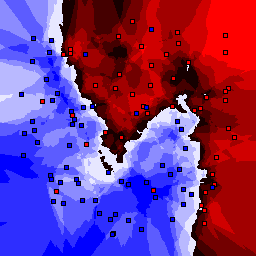
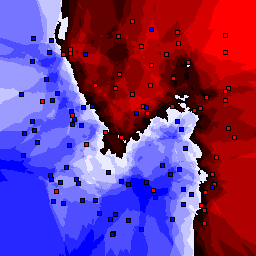
15% outliers Binary |

|
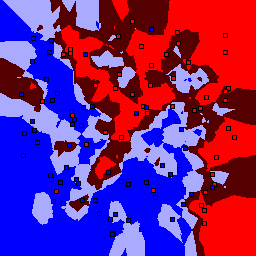
|
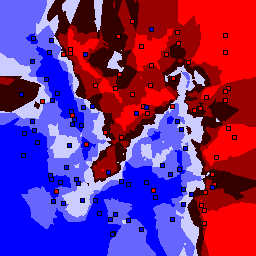
|
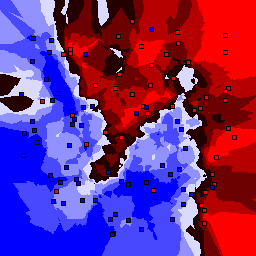
|
|
|
|
|
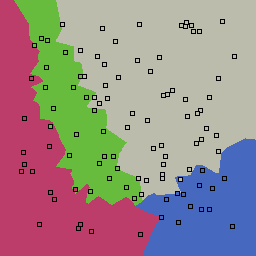
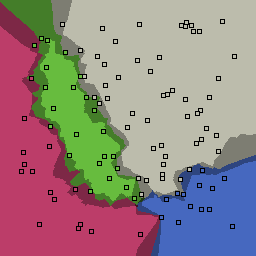
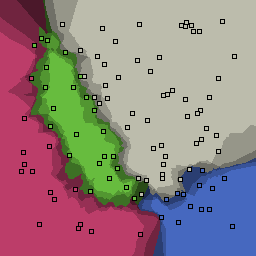
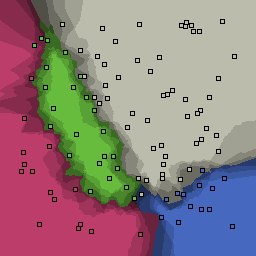
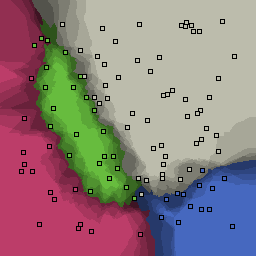
0% outliers Multiclass |
|
|
|
|
|
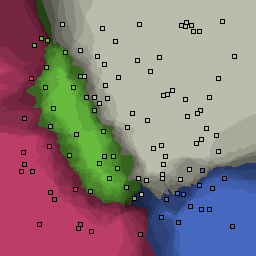
|
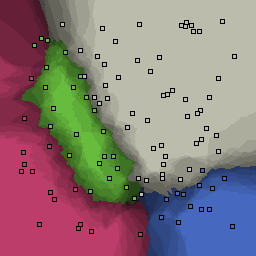
|
|
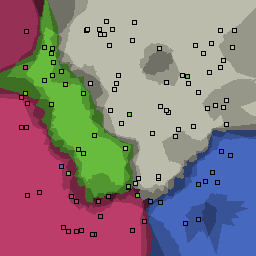
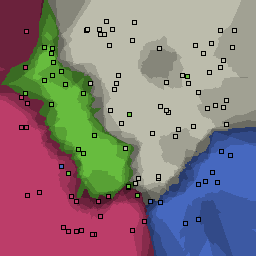
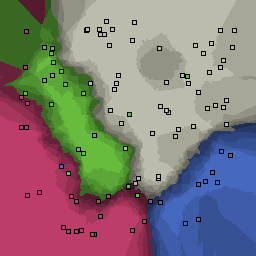
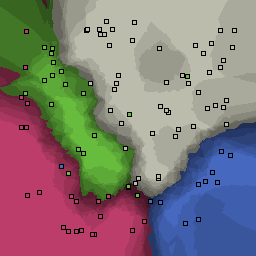
5% outliers Multiclass |
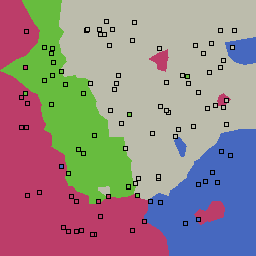
|
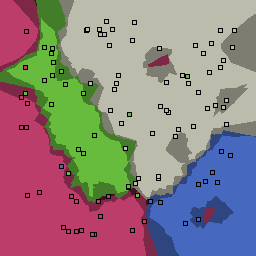
|
|
|
|
|
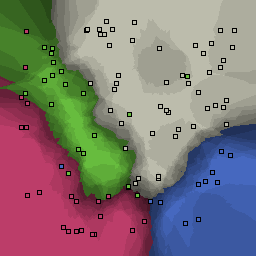
|
|
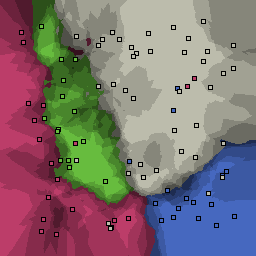
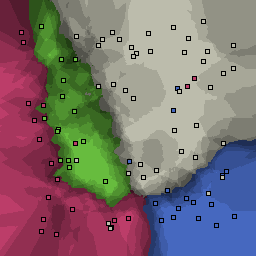
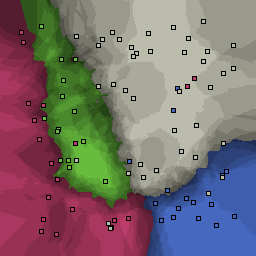
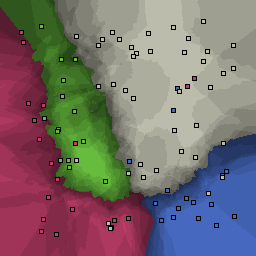
15% outliers Multiclass |
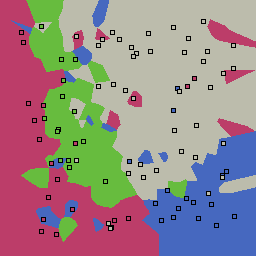
|
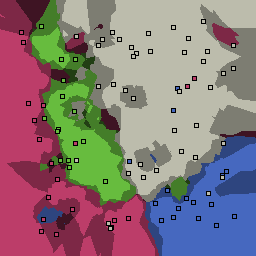
|
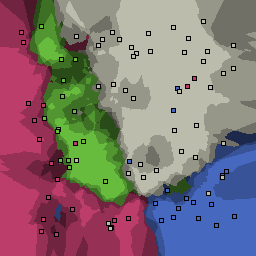
|
|
|
|
|
Nearest neighbor learners have many nice properties -- for example, they always converge to the "correct" solution in the limit as the number of examples increases. Nearest neighbor works very well on this problem because the dimesionality is so low and the behavior is relatively low frequency. As the dimensionality of the input increases, nearest neighbor is very sensitive to the relative weighting of the dimensions and the presence of noisy dimensions that do not correlate with the objective function.
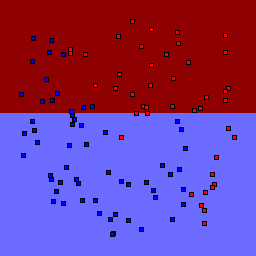
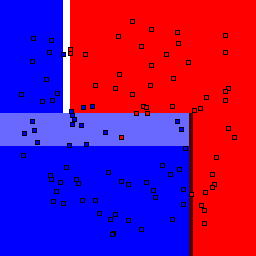
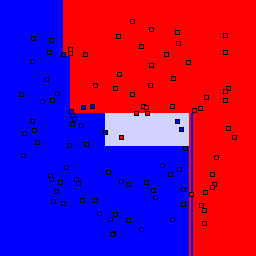
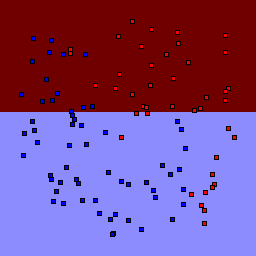
Decision Tree
| Tree Depth | 1 | 2 | 3 | 4 | 5 | 7 | 9 |
|
0% outliers Binary |
|

|
|
|

|

|

|
|
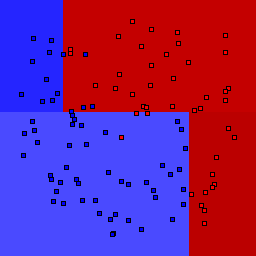
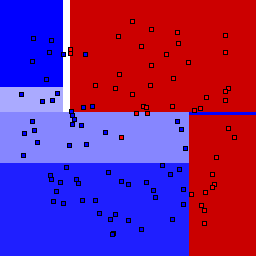
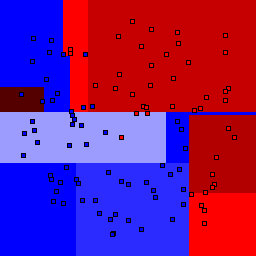
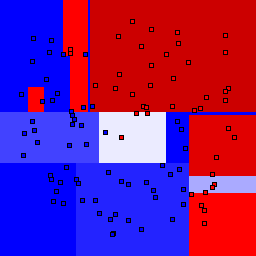
5% outliers Binary |
|
|
|
|
|

|
|
|
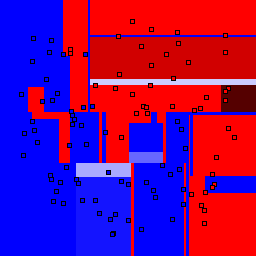
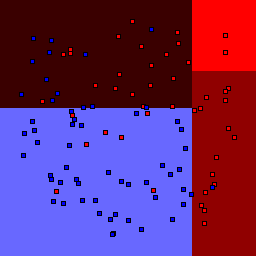
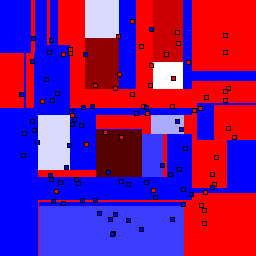
15% outliers Binary |

|
|

|

|

|

|
|
|
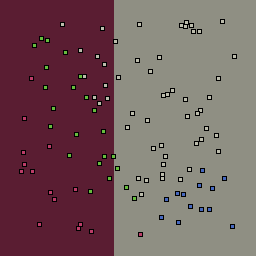
0% outliers Multiclass |
|
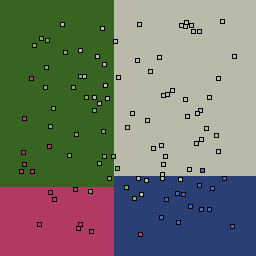
|
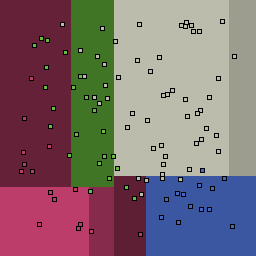
|

|
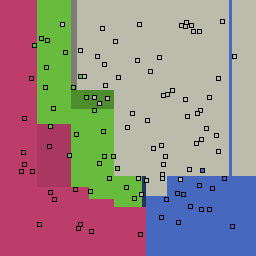
|
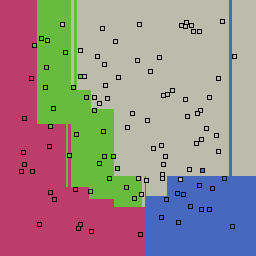
|
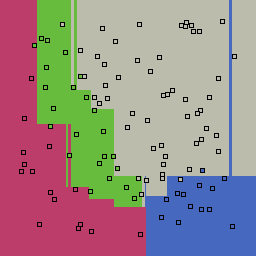
|
|
5% outliers Multiclass |

|

|

|

|

|
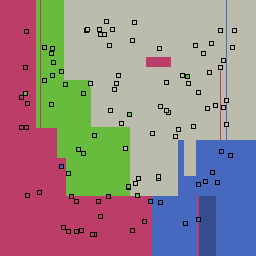
|
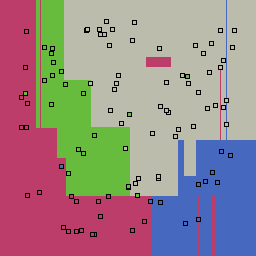
|
|
15% outliers Multiclass |

|

|

|

|

|

|
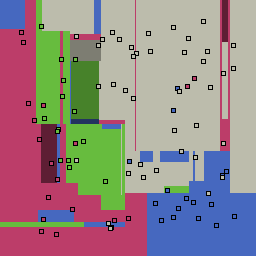
|
Decision trees can get into trouble because there is no known way to efficiently find the optimal decision tree, and in this implementation, decision splits are all axis-aligned. As can be easily seen, they also deal poorly with outliers when only a small number of training samples are available and in the presence of completely unstructured noise. This can result in some very odd decision boundaries -- meta techniques like bagging and boosting are very useful for smoothing over these artifacts.
Boosted Decision Trees
These results use the AdaBoost algorithm using decision trees of the given tree depth as base classifiers.
| Tree Depth | 1 | 2 | 3 | 4 | 5 | 7 | 9 |
|
0% outliers Binary |
_boostCount=100_depth=1.png)
|
_boostCount=100_depth=2.png)
|
_boostCount=100_depth=3.png)
|
_boostCount=100_depth=4.png)
|
_boostCount=100_depth=5.png)
|
_boostCount=100_depth=7.png)
|
_boostCount=100_depth=9.png)
|
|
5% outliers Binary |
_boostCount=100_depth=1.png)
|
_boostCount=100_depth=2.png)
|
_boostCount=100_depth=3.png)
|
_boostCount=100_depth=4.png)
|
_boostCount=100_depth=5.png)
|
_boostCount=100_depth=7.png)
|
_boostCount=100_depth=9.png)
|
|
15% outliers Binary |
_boostCount=100_depth=1.png)
|
_boostCount=100_depth=2.png)
|
_boostCount=100_depth=3.png)
|
_boostCount=100_depth=4.png)
|
_boostCount=100_depth=5.png)
|
_boostCount=100_depth=7.png)
|
_boostCount=100_depth=9.png)
|
|
0% outliers Multiclass |
_boostCount=100_depth=1.png)
|
_boostCount=100_depth=2.png)
|
_boostCount=100_depth=3.png)
|
_boostCount=100_depth=4.png)
|
_boostCount=100_depth=5.png)
|
_boostCount=100_depth=7.png)
|
_boostCount=100_depth=9.png)
|
|
5% outliers Multiclass |
_boostCount=100_depth=1.png)
|
_boostCount=100_depth=2.png)
|
_boostCount=100_depth=3.png)
|
_boostCount=100_depth=4.png)
|
_boostCount=100_depth=5.png)
|
_boostCount=100_depth=7.png)
|
_boostCount=100_depth=9.png)
|
|
15% outliers Multiclass |
_boostCount=100_depth=1.png)
|
_boostCount=100_depth=2.png)
|
_boostCount=100_depth=3.png)
|
_boostCount=100_depth=4.png)
|
_boostCount=100_depth=5.png)
|
_boostCount=100_depth=7.png)
|
_boostCount=100_depth=9.png)
|
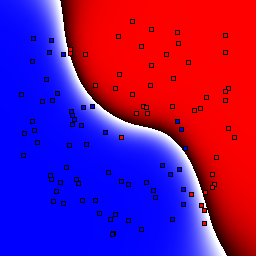
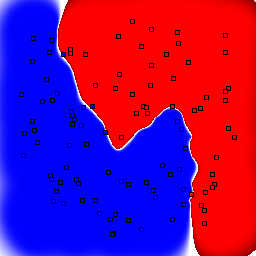
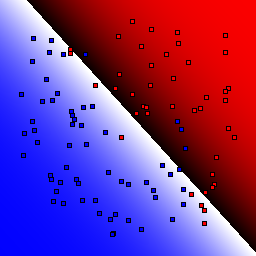
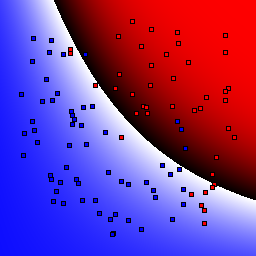
Support Vector Machines
These results use C=1 for the soft margin parameter.
| Kernel | Linear | Quadratic | Cubic | Quartic | Gaussian, σ=0.1 | Gaussian, σ=1.0 | Gaussian, σ=10.0 |
|
0% outliers Binary |

|

|

|

|
|

|
|
|
5% outliers Binary |
|
|

|

|

|
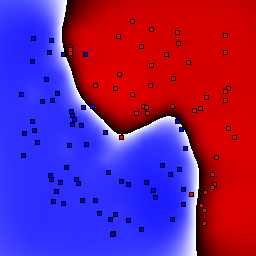
|
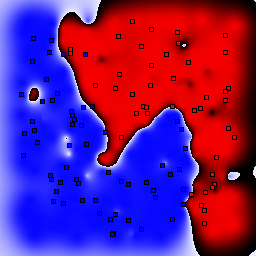
|
|
15% outliers Binary |
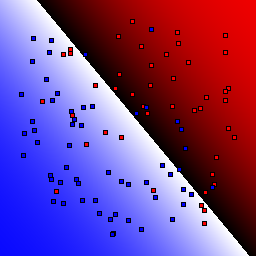
|
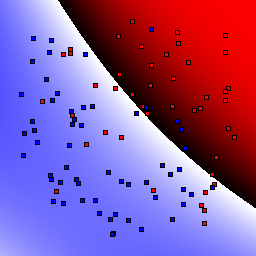
|

|

|
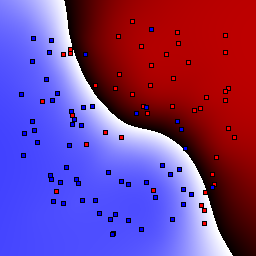
|
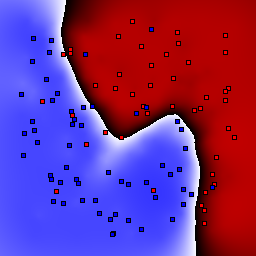
|
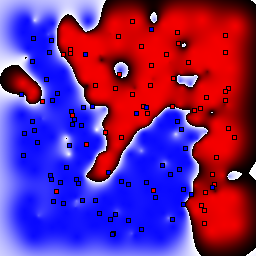
|
|
0% outliers Pairwise Coupling |
_C=1.0_kernel=linear.png)
|
_C=1.0_kernel=quadratic.png)
|
_C=1.0_kernel=cubic.png)
|
_C=1.0_kernel=quartic.png)
|
_C=1.0_kernel=gaussian0.png)
|
_C=1.0_kernel=gaussian1.png)
|
_C=1.0_kernel=gaussian2.png)
|
|
5% outliers Pairwise Coupling |
_C=1.0_kernel=linear.png)
|
_C=1.0_kernel=quadratic.png)
|
_C=1.0_kernel=cubic.png)
|
_C=1.0_kernel=quartic.png)
|
_C=1.0_kernel=gaussian0.png)
|
_C=1.0_kernel=gaussian1.png)
|
_C=1.0_kernel=gaussian2.png)
|
|
15% outliers Pairwise Coupling |
_C=1.0_kernel=linear.png)
|
_C=1.0_kernel=quadratic.png)
|
_C=1.0_kernel=cubic.png)
|
_C=1.0_kernel=quartic.png)
|
_C=1.0_kernel=gaussian0.png)
|
_C=1.0_kernel=gaussian1.png)
|
_C=1.0_kernel=gaussian2.png)
|
|
0% outliers One vs. All |
_C=1.0_kernel=linear.png)
|
_C=1.0_kernel=quadratic.png)
|
_C=1.0_kernel=cubic.png)
|
_C=1.0_kernel=quartic.png)
|
_C=1.0_kernel=gaussian0.png)
|
_C=1.0_kernel=gaussian1.png)
|
_C=1.0_kernel=gaussian2.png)
|
|
5% outliers One vs. All |
_C=1.0_kernel=linear.png)
|
_C=1.0_kernel=quadratic.png)
|
_C=1.0_kernel=cubic.png)
|
_C=1.0_kernel=quartic.png)
|
_C=1.0_kernel=gaussian0.png)
|
_C=1.0_kernel=gaussian1.png)
|
_C=1.0_kernel=gaussian2.png)
|
|
15% outliers One vs. All |
_C=1.0_kernel=linear.png)
|
_C=1.0_kernel=quadratic.png)
|
_C=1.0_kernel=cubic.png)
|
_C=1.0_kernel=quartic.png)
|
_C=1.0_kernel=gaussian0.png)
|
_C=1.0_kernel=gaussian1.png)
|
_C=1.0_kernel=gaussian2.png)
|
Code
This code is all based off my BaseCode. Specifically you will need the contents of Includes.zip on your include path, Libraries.zip on your library path, and DLLs.zip on your system path.
![]() MachineLearning.zip (includes project file)
MachineLearning.zip (includes project file)
MachineLearning Code Listing
Total lines of code: 920
Engine Code Listing
Total lines of code: 4274