Scene Reconstruction
Scene reconstruction is the process of reconstructing a digital version of a real world object from pictures or scans of the object. It is a very complex problem with a lot of research history, open problems, and possible solutions. I am very interested in the problem because I think it would be excellent to have a program that lets people who just have a point-and-shoot camera create textured 3D models. Cameras are widely accessible and it would make very high-quality 3D model generation possible for non-artists. I feel that such a program is certainly possible by combining several existing techniques, people have just yet to put it all together. Most approaches to this problem can be broken down into two broad phases: first, you take your input and turn it into a cloud of points on the surface of the object, and then you reconstruct a mesh from this point cloud.
I'll start off by showing my results and comparing them against some state-of-the-art algorithms, then briefly describe how the algorithm works. Although I haven't worked on this problem since 2008, the advent of cheap cameras with limited depth perception such as the Xbox's Kinect sensor may motivate me to revisit this problem in the near future.
Results
The Multi-View Stereo Dataset is a standard dataset for this problem. The input images were generated using the Stanford Spherical Gantry, which results in images that are much better quality than could be expected in practice. Nevertheless, they offer a good upper bound on the mesh quality that can be achieved, and are a good way of comparing various algorithms for this problem. The two standard test cases are the Temple and Dino scenes:


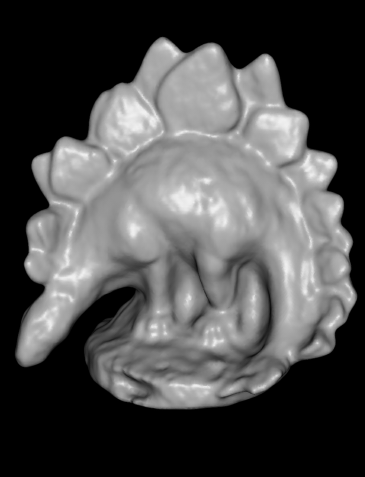
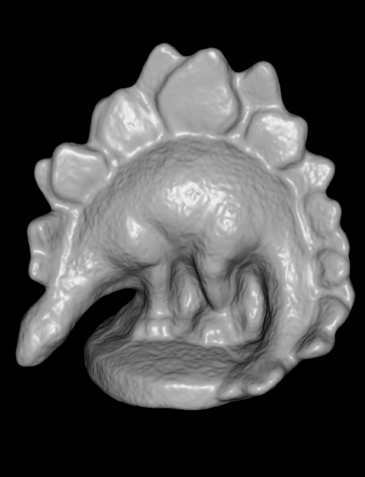
The input consists of a number of 640x480 photographs and the goal is to produce a mesh that approximates the object. The datasets vary in difficulty based on the numbers of photographs provided; most results I will show use the "ring" version of the dataset, which uses 47 images in a ring around each object. The dino is an especially challenging object because the very smooth shading does not contain many high frequency features that computer vision algorithms can match between images. Here is a table comparing my results against Yasutaka Furukawa's method, which at present is one of the best algorithms available, and is also the algorithm closest to my own:
|
|
|
|

|

|

|

|
|
|
Texture
The ground truth was generated by scanning the objects with a 3D scanner and is a much higher resolution reconstruction than is possible from the 640x480 input images. Although my method looks slightly more blurry than Furukawa's implementation, it still captures much of the structure of the objects correctly (and looks much better when you compare it against the other entries on the Multi-View Stereo Dataset site.) Although it may look like these algorithms miss important details, we can texture the resulting mesh using the input images. Since humans derive such strong visual cues from the shading, the texture dominates our perception of the object and it is very hard to see the small imperfections in the geometry. Here are results using my algorithm with texturing:

|

|
|

|

|

|
|

|
Mesh and Atlas
To perform the texturing, I first generate an atlas using the UVAtlas tool that comes with Direct3D 9. Then for each pixel in the atlas, I look at the corresponding point on the mesh and project it into each input image that can see this point. After some filtering to remove outliers, a voting procedure across the images is used to determine the best color for this pixel. Below I show the mesh with its atlas segmentation and the corresponding texture. On the right, I also show the triangles in the generated mesh (although it is very easy to produce meshes with a different triangle density.)

Videos
Below are videos of the reconstruction, showing one spin around the object rendered as a mesh, and one spin using the textured mesh. Unfortunately, the codec I used seems to not be a very standard codec, and I don't have the original images to re-encode them in H.264. TempleFull is the reconstruction using the entire dataset rather than just the 47 images in the ring dataset.
![]() Dino.avi
Dino.avi
![]() Temple.avi
Temple.avi
![]() TempleFull.avi
TempleFull.avi
Method
All algorithms that do this reconstruction are very complex and are composed of a large number of parts. I made a PowerPoint presentation that gives a good summary of the method. In brief, it starts with a candidate mesh to generate a set of depth maps in each image. A variant of Yasutaka Furukawa's method is then used to optimize these depth maps. This optimization is extremely slow on the CPU, but my implementation was done on the GPU which makes it dramatically faster (Furukawa reported a runtime of 10 hours while my meshes take about 15 minutes to generate.) The depth maps are turned into a point cloud, and this cloud is then reconstructed using Poisson Surface Reconstruction. I then project this new mesh back into each camera to produce new depth maps, and iterate this optimization and reconstruction procedure multiple times until the resulting mesh converges to a good solution.