Vladlen Koltun
[personal website]
Inverse optimal control, also known as inverse reinforcement learning, is the problem of recovering an unknown reward function in a Markov decision process from expert demonstrations of the optimal policy. We introduce a probabilistic inverse optimal control algorithm that scales gracefully with task dimensionality, and is suitable for large, continuous domains where even computing a full policy is impractical. By using a local approximation of the reward function, our method can also drop the assumption that the demonstrations are globally optimal, requiring only local optimality. This allows it to learn from examples that are unsuitable for prior methods.
ErratumThe equation for the state-action Jacobian in Section 5 is incorrectly indexed. The correct equation is given below.
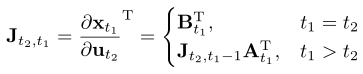
Video: [MP4]
Source Code (MATLAB): [ZIP]
BibTeX Citation
@inproceedings{2012-cioc,
author = {Sergey Levine and Vladlen Koltun},
title = {Continuous Inverse Optimal Control with Locally Optimal Examples},
booktitle = {ICML '12: Proceedings of the 29th International Conference on Machine Learning},
year = {2012},
}