Kinect

The Kinect is an attachment for the Xbox 360 that combines four microphones, a standard RGB camera, a depth camera, and a motorized tilt. Although none of these individually are new, previously depth sensors have cost over $5000, and the comparatively cheap $150 pricetag for the Kinect makes it highly accessible to hobbyist and academics. This has spurred a lot of work into creating functional drivers for many operating systems so the Kinect can be used outside of the Xbox 360. You can find a decent overview of the current state of people working on Kinect here. I decided to hack around with the Kinect partially because Pat Hanrahan bought us a Kinect and partially becauase I wanted to see if it had a good enough resolution to be used for my scene reconstruction algorithm. I also think the Kinect has pretty significant implications for cheap robotics projects that I might one day work on.
Drivers
There are a lot of different people working on different drivers for different operating systems. Since I do most of my research code on Windows I figured I would start looking for Kinect drivers there. At first I tried to hack up some general-purpose code using cygwin and the code at this git repo combined with some libusb-1.0 backend for Windows. Although I did get things compiling, the code was very hobbled together and couldn't connect to the sensor correctly. Then I found this amazing site. The SDK contains drivers for the motor and camera and has an extremely simple interface nicely wrapped in a single DLL, header, and library. The sample WPF application shows how to access all these functions and the interface to the Kinect is exactly what you would expect. Anyone working on Kinect on Windows should start here, and from what I've experimented with this SDK is in much better shape than the libfreenect code. OpenKinect.org is a good reference for people working on Kinect and talks about a lot of useful specifics such as how to interpret the raw sensor values. There is a great description of how the Kinect was reverse-engineered here with lots of generally applicable descriptions for studying and working with USB streams.
The drivers don't do any postprocessing on the data, they just give you access to the raw data stream from the Kinect and let you control the LED and motor. Here I've colored the depth camera using a continuous rainbow-like color scheme where red is closest and white is farthest.
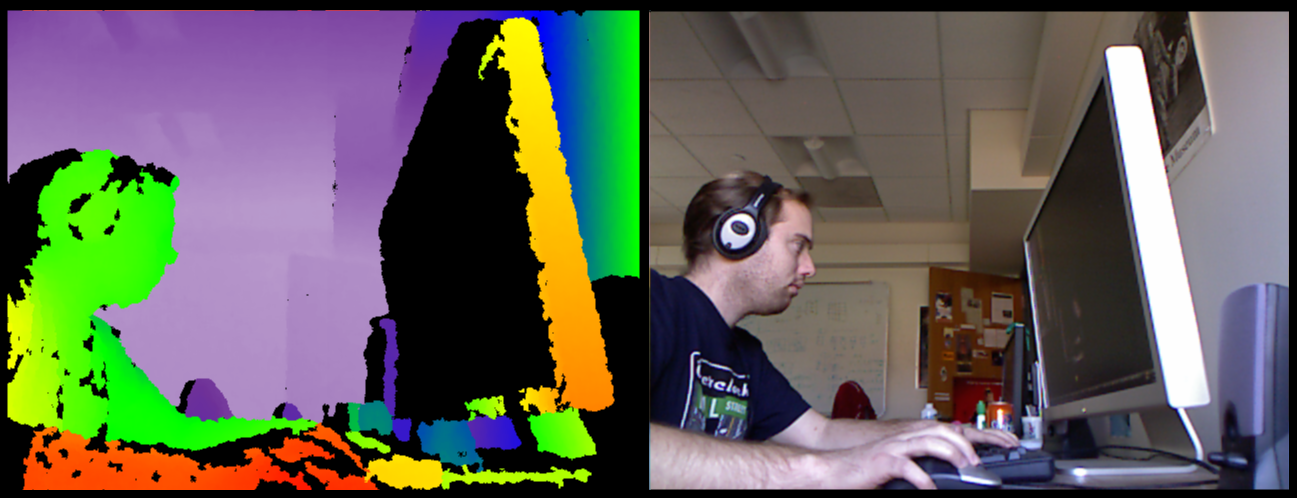
Audio
Most people talking about the Kinect are focusing on the depth sensor. While the availability of a cheap depth sensor is central to the Kinect's appeal to hobbyists, the multiple microphones on the Kinect should not be overlooked. Having multiple microphones allows you to use algorithms such as independent component analysis to perform speaker isolation and noise cancellation. When I implemented this algorithm in CS 229 at Stanford, the results were quite impressive and it was able to almost perfectly detangle five unique speakers given five microphones recording the audio of five different sound emitters playing in a room. When used on the Kinect's microphone array this should result in extremely crisp noise filtering and be able to isolate cross-talk between simultaneous speakers, which will in turn allow for high accuracy voice recognition and confrencing between XBoxes.
Interpreting Sensor Values
The raw sensor values returned by the Kinect's depth sensor are not directly proportional to the depth. Instead, they scale with the inverse of the depth. People have done relatively accurate studies to determine these coefficients with high accuracy, see the ROS kinect_node page and work by Nicolas Burrus. Both of these are excellent resources for working with the depth and color cameras. Here is a picture of the Kinect sensor output that I took from a YouTube video:

The highly unstructured (but not fully random) nature of these points helps remove aliasing in the depth camera errors. Although I can't find anyone to confirm this, my guess is that the each depth pixel is computed by sampling the derivative of the higher resolution infrared image taken by the infrared camera. This value would be inversely proportional to the radius of each gaussian dot, which is linearly proportional to the actual depth.
The Kinect reads infrared and color data with different cameras. This makes it very challenging to determine the color of a given depth pixel or the depth of a given color pixel. Doing this requires knowing the intrinsic parameters of both cameras (they are similar, but not identical) and knowing the extrinsic mapping between them. Doing this correctly involves working with things like OpenCV which can be kind of a slow for realtime applications and can be a frustrating library to interact with in general. This calibration is also challenging because the depth camera can't see simple checkerboard patterns - it needs a checkerboard pattern that also contains regular and calibrated depth disparities. Fortuantely Nicolas Burrus posted the calibration for his Kinect color and depth cameras here, which gave pretty good results for my Kinect although there was still some noticeable misalignment.
Below is are the functions I used to do this mapping. DepthToWorld maps from the depth camera's (i, j, v) into world coordinates. WorldToColor maps a point in world coordinates into the pixel indices in the color camera. These functions ignore the distortion effects of the lens, but still give reasonably accurate results. These rely on my matrix and vector classes, but your graphics API probably has similar functions built-in.
{
if (depthValue < 2047)
{
return float(1.0 / (double(depthValue) * -0.0030711016 + 3.3309495161));
}
return 0.0f;
}
Vec3f DepthToWorld(int x, int y, int depthValue)
{
static const double fx_d = 1.0 / 5.9421434211923247e+02;
static const double fy_d = 1.0 / 5.9104053696870778e+02;
static const double cx_d = 3.3930780975300314e+02;
static const double cy_d = 2.4273913761751615e+02;
Vec3f result;
const double depth = RawDepthToMeters(depthValue);
result.x = float((x - cx_d) * depth * fx_d);
result.y = float((y - cy_d) * depth * fy_d);
result.z = float(depth);
return result;
}
Vec2i WorldToColor(const Vec3f &pt)
{
static const Matrix4 rotationMatrix(
Vec3f(9.9984628826577793e-01f, 1.2635359098409581e-03f, -1.7487233004436643e-02f),
Vec3f(-1.4779096108364480e-03f, 9.9992385683542895e-01f, -1.2251380107679535e-02f),
Vec3f(1.7470421412464927e-02f, 1.2275341476520762e-02f, 9.9977202419716948e-01f));
static const Vec3f translation(1.9985242312092553e-02f, -7.4423738761617583e-04f, -1.0916736334336222e-02f);
static const Matrix4 finalMatrix = rotationMatrix.Transpose() * Matrix4::Translation(-translation);
static const double fx_rgb = 5.2921508098293293e+02;
static const double fy_rgb = 5.2556393630057437e+02;
static const double cx_rgb = 3.2894272028759258e+02;
static const double cy_rgb = 2.6748068171871557e+02;
const Vec3f transformedPos = finalMatrix.TransformPoint(pt);
const float invZ = 1.0f / transformedPos.z;
Vec2i result;
result.x = Utility::Bound(Math::Round((transformedPos.x * fx_rgb * invZ) + cx_rgb), 0, 639);
result.y = Utility::Bound(Math::Round((transformedPos.y * fy_rgb * invZ) + cy_rgb), 0, 479);
return result;
}
Once you have calibrated the depth and color sensors, you can pretty easily make a colored mesh of the 3D environment, which is very useful when writing and debugging applications that use the Kinect. Because generating a 3D mesh requires choosing arbitrary cutoff factors to determine which edges correspond to depth discontinuities, I instead use a simpler point cloud approach where I render a colored set of spheres.

Painting
I am currently working on a program that lets you use a rectangle you define in the air or on an existing surface (such as your monitor) as a canvas or tablet. This has interesting implications because unlike a normal tablet the Kinect can measure any distance between your stylus and the surface, and not just physical contact. Furthermore, the stylus can be anything from your hand to a real paint brush. Unfortunately the depth sensor approach has many quirks that can result in loss of tracking or weird results. For example, you have to make sure not to occlude the depth sensor as you draw, and your stylus has to be big enough that it can be resolved by the depth sensor at any point on the canvas. My current prototype works relatively well and based on my few experiments, a stylus the size of a dry erase marker will never lose tracking but one the size of an index finger will only be trackable about 90% of the time. I'm currently working on coming up with intuitive mappings from brush motions to painting operations, and will post a video and code when I have time, but unfortunately my schedule is rather busy until SIGGRAPH papers are due in late January. I recently found this YouTube video of a Kinect being used to drive a Microsoft Paint program and demonstrates very impressive drawing accuracy.