The H3 layout scheme consists of two parts: we must first find an appropriate spanning tree from an input graph. We then determine a position in space for each element of that tree in space. Non-tree links do not affect the layout decision, and are only drawn on request. The spanning tree links are always drawn. We lay out the entire structure and then change the focus by hyperbolic navigation. This section contains a discussion of our layout approach and Appendix A contains a detailed derivation of the hyperbolic layout parameters.
The choice of spanning tree is fundamental in shaping the visualization of the graph. While we can construct a spanning tree based only on the link structure of the graph, domain-specific knowledge will usually help impose a tree structure that matches the user's expectations. Our current system uses domain knowledge to disambiguate, not override, the link structure of the graph. We discuss examples in three domains:
![]() Directory structure of a Unix file system
Directory structure of a Unix file system
Leaf nodes represent files and interior nodes represent directories. File systems tend to be nearly trees: nontree edges represent symbolic links, which are relatively rare. The full path name of a file mirrors the link structure of the input graph, so domain knowledge is not important in this case.
![]() Hyperlink structure of the Web
Hyperlink structure of the Web
Nodes represent Web documents and the links represent hyperlinks between those documents. The link structure is usually quite different from the directory structure in which those documents are kept on the file system. When we simply use the link traversal of the graph to determine parentage, the resulting tree is generally not very close to the authorial intent of the Web designer. For instance, the top-level document at a site may contain a link to a table of contents page, which in turn contains a link to every other document at that site. According to the link structure of the graph, that table of contents document would be the main parent of most of those nodes. The URL encodes the place of a Web document in the Unix directory structure. We use this directory information to make a decision to decide which of the hyperlinks to a document should be used as its main parent in the tree. Note that this use of directory information to resolve parentage within the context of the link structure is not the same as simply laying out a graph of the file system. We also use the Web domain knowledge that file names ending in i.e. index.htm should be the parent of other files which share a directory.
One advantage of this heuristic is that it makes a common breakdown very visible to the user. Orphan documents are those whose directory-structure parents are not listed as possible parents in the link traversal of the graph. Orphans are often the result of inadvertently broken links. Our heuristic places these nodes near the top of the tree rather than among their directory-structure peers, so they stand out.
![]() Function call graphs
Function call graphs
Nodes represent functions and the links represent a call from one function to another. Our example is a call graph for a FORTRAN scientific computing benchmark. Although we cannot simply glean hierarchical information from function names, we can use a combination of compiler analysis and dynamic profile information to determine a reasonable spanning tree. The calling procedure which is responsible for the majority of the child's execution time is chosen as the main parent.
In traditional cone trees nodes are laid out on a circle: the circumference of the disc at the bottom of the cone. In the H3 algorithm we lay them out on a hemisphere: a spherical cap which covers the cone mouth. Figure 2a compares the two layouts for the same data set, a single generation of children. We use hemispheres instead of full spheres since we only have an exponential amount of room when in the direction radially outward from the origin.
The algorithm requires two passes: a bottom-up pass to determine the radius of the hemispheres, and a top-down pass to lay out the child nodes on the surface of their parental hemisphere. We cannot combine these steps because we must know the radius of the parent hemisphere before we can compute the final position of each child hemisphere.
![]() Bottom-up pass:
Bottom-up pass:
We know the radius of each of the child hemispheres and must determine how large of a hemisphere to allocate for the parent hemisphere. Ideally we would consider the area of the spherical caps covered by child hemispheres, and sum them to get the necessary area for the parent hemisphere. However, the computation of the area of spherical cap requires knowledge about the radius of the parental hemisphere, which is just what we are trying to find. We instead use the area of the disc at the bottom of the child hemisphere as an acceptable approximation. This approximation is quite close when the child hemisphere subtends a small angle; that is, when a parent has many child nodes. The approximation breaks down when the number of children is very small, but this situation is easy to handle with special cases. Leaf nodes are drawn as tetrahedra of a fixed hyperbolic size in this implementation, so we know the value of the radius in the base case.
![]() Top-down pass:
Top-down pass:
We know at every level the radius of the parent hemisphere but must decide how to lay out the children on its surface. This decision is an instance of the sphere-packing problem, which has been extensively explored by mathematicians. Our particular instance is that of packing 1-spheres (i.e. circles) on the surface of a 2-sphere (i.e. an ordinary sphere) [CS88]. A related problem is that of distributing points evenly on a sphere [SK97].
The particular requirements of our situation are somewhat different than the usual cases addressed in the literature. Our circles are of variable size, and we are interested in a hemisphere as opposed to a sphere. More importantly, our solution must be fast and repeatable. Our solution cannot involve randomness: given the same input, we must generate the same canonical output. We care far more about speed than precision. An approximate layout is fine for our purposes, while a perfect but slow iterative solution would be inappropriate.
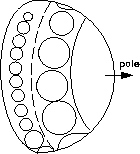
Our solution is to lay out the discs in concentric bands centered along the pole normal to the sphere at infinity. We sort the child discs by the size of their hemispheres. This number, which is recursively calculated in the first bottom-up pass, depends on the total number of their descendants, not just their first-generation children. The ones which require the most area (i.e. the ones with the most progeny) are closest to this pole. Figure 3 shows a view of a parent hemisphere from the side, drawing only the footprints of the child hemispheres. The equatorial (bottom-most) band is usually only partially complete.
One advantageous result of our choice to order by number of progeny is that the complex part of structures is always easy to locate. An investigation of the tradeoffs of other ordering criteria would be worth undertaking.
Figure 3: Disks at the bottom of child hemispheres are laid out in bands on the parent in sorted order according to the number of their descendants, with the most prolific at the pole.
Even if our circle packing were optimal, the area of the hemisphere required to accommodate the circles would be greater than the sum of the spherical caps subtended by those circles, since we do not take into account the uncovered gaps between the circles. Moreover, our banding scheme, while relatively easy to implement, is definitely a suboptimal circle packing. We waste the leftover space in the equatorial band, which in the worst case contains only a single disc. If we did not sort the child discs by size the discrepancy would be even worse. Finally, the above-mentioned difference between the area of a disc and the area of the spherical cap contributes to the total discrepancy
We chose to deal with this discrepancy by increasing the radius of the parental hemisphere by a factor proportional to the originally computed radius. A possible alternative would be to use the computed radius as the base for an iterative solution. While this iteration would probably converge quickly, our empirically derived factor works well in practice.
Figure 4 is a sequence showing motion through several generations of a tree representing a Unix file system of 2000 nodes.