Rasterization problem: Frequently Asked Questions
- If you control both the hardware and the software, why don't they
do what you want them to do? Wouldn't it make more sense to
investigate how you'd add programmable elements to the proven triangle
processor design?
- Are you computing eight different triangles at the same time, or
are you working on different pixels of the same triangle? If working
on different triangles, why? Are the costs of communication between
the arithmetic clusters so high?
- What are the real costs of this "select" function?
- You don't mention any "costs" for accessing external memory.
- Just knowing if the pixel is inside the triangle is not enough for
rasterization. You also need to compute depth and shading information.
Could you work that into the loop? You should be able to hide your
latency with this additional computation.
- Why not the bounding box? The math to traverse the bounding box is
very simple.
- Why not quadtree traversal?
- Can you work on several triangles simultaneously?
- How are cctoi and itocc actually handled in the hardware?
1: If you control both the hardware and the software, why don't they
do what you want them to do? Wouldn't it make more sense to
investigate how you'd add programmable elements to the proven triangle
processor design?
Answer: One of the key areas of our research is exploring how we can do
with only programmable hardware. Modern microprocessors also have only
programmable hardware, but they are not able to apply the number of
functional units or the necessary data bandwidth to the problem like
we can.
Current graphics hardware is rapidly becoming more programmable. In
general, graphics vendors have been adding programmability by
beginning with specialized hardware and adding programmable elements.
We are taking the opposite approach: begin with a fully programmable
machine, and explore from that what specialization might be useful for
graphics.
Our processor is targeted at a wide range of media applications,
including image, signal, and video processing. We haven't put in any
specialization for graphics (or other application domains). There is
no question that a hardware rasterizer (for instance) would help
performance and would solve this problem, but that's not an option.
It's an avenue I intend to explore in my research -- what hardware
specialization might make this architecture better suited for graphics
-- but right now I am trying to solve the problem with the fully
programmable hardware we built.
In any event, we culminated our four-year design process by sending
the top-level design to the foundry last week. So there won't be any
more hardware changes.
2: Are you computing eight different triangles at the same time, or
are you working on different pixels of the same triangle? If working
on different triangles, why? Are the costs of communication between
the arithmetic clusters so high?
Answer: Each cluster works on a different triangle. One reason for this is
because the inter-cluster bandwidth is not nearly as large as the
bandwidth within a cluster (inter-cluster bandwidth is only one word
read and one word written per cluster per cycle). Imagine does not
have a high-bandwidth intercluster broadcast mechanism.
But a better reason is because I am making sure that small triangles
will be rasterized efficiently -- I don't want to optimize for large
triangles. If 8 clusters all worked on the same triangle, then they
would output a minimum of 8 pixels for that triangle. Especially for
small triangles, many of those pixels might not be valid, and we are
trying to make our percentage of valid pixels as large as possible.
The UNC PixelPlanes machine did exactly this: it had SIMD hardware,
but used it to work on different pixels of the same triangle at the
same time. This is efficient for large triangles where the number of
pixels per triangle is considerably greater than the number of SIMD
units, but as triangles grow smaller, it becomes less efficient.
A final reason is that we'd like the algorithm to be generalizable to
more clusters - 16 or 32. As the width of the machine increases, and
triangles get smaller, it gets harder and harder to get performance
gains by working on only one triangle at the same time.
3: What are the real costs of this "select" function?
Answer: The select function is actually really cheap. It's a one-cycle
function that can be executed on any functional unit (adders,
multipliers, divider, or comm unit). So we can issue 7 selects per
cluster every cycle. This is handy when selecting large records. For
example, the prepped triangle has 8 words in it. We can select between
two triangles in 1 cycle + 1 issue slot of a second cycle.
In practice, since the divider isn't used in this algorithm, many of
the selects will be executed on it and not use the issue slots of the
adders or multipliers.
4: You don't mention any "costs" for accessing external memory.
Answer: In this operation, you shouldn't have to access external memory.
The only information you need to evaluate which pixels are covered is
the triangle, which is on the order of 10 words, and any state you
care to store during the computation. A cluster has over 200 words of
local storage in register files (and another 256 words in the stream
register file), so all computation can -- and should be -- local,
without using any external memory.
5: Just knowing if the pixel is inside the triangle is not enough for
rasterization. You also need to compute depth and shading information.
Could you work that into the loop? You should be able to hide your
latency with this additional computation.
Answer: This is an excellent question and goes to the heart of how we
designed our rasterizer. Short answer: We are attempting to completely
separate pixel coverage from interpolation, and are only considering
the pixel coverage information.
Originally, we calculated pixel coverage (which pixels are covered by
the triangle) and interpolation (interpolating the color, depth, etc.
parameters across the triangle) at the same time. Most scanline
rasterizers do this: as you traverse a span, for example, you
incrementally compute the interpolants, doing one add per pixel per
interpolant. This algorithm is efficient in terms of computation.
Unfortunately, as the number of interpolants grew very large (one of
our programmable shaded objects, the UNC bowling pin, had 30
interpolants), the amount of local storage needed to handle all the
computation was much larger than our hardware could allow. We would
like to be able to handle an arbitrary number of interpolants, and
wanted to design algorithms which would allow us to do so.
The insight that made this possible was the separation of pixel
coverage from interpolation. If we compute all the pixel locations
first, we know that's a tractable problem (it's the exact problem I'm
posing here). Then, even with a huge number of interpolants, we can
process the many interpolants in smaller batches which will fit on our
hardware with little to no performance loss. The interpolation step,
once pixel coverage and barycentric coordinates at each of those
pixels is calculated, is a separable computation, and efficiently so.
For this to work, however, it is necessary to have an efficient pixel
coverage algorithm, which is why I posed this question.
6: Why not the bounding box? The math to traverse the bounding box is
very simple.
Answer: Agreed on the math. But the percentage of invalid pixels generated
is just too large. In the best case the bounding box will only have a
50% valid-pixel rate, and the worst case (skinny diagonal triangles),
the percentage of valid pixels is very low. Because I have to compute
all the pixel coverage information in just this one loop, I can't go
back and clean it up later by removing the invalid pixels from the
stream. (I lose the ordering information needed in later steps if I do
so.)
7: Why not quadtree traversal?
Answer: 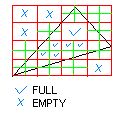
(Thanks to Lukasz Piwowar for this picture.) A quadtree is
efficient for large triangles, but as triangles become smaller (1-5
pixels) the overhead due to the traversal is large compared to the
amount of work spent per pixel.
8: Can you work on several triangles simultaneously?
Answer: Unfortunately, no (although it would really help throughput). The
reason is because when I output pixels, I have to output all pixels
from the same triangle sequentially without interruption from other
pixels from other triangles. Also, I need to maintain ordering on the
triangles, so I can't, say, chop the input stream of triangles in half
and work on the first half and second half simultaneously.
9: How are cctoi and itocc actually handled in the hardware?
Answer: For the purposes of this discussion, condition codes (cc) are
stored in a one-bit wide register file. (They're actually 4 bits wide
and can select on a byte basis, but we're not doing that here.) So
itocc(i) just takes the low word of i, and cctoi(c) replicates the bit
in c across all bits (cctoi either outputs 0 or 0xffffffff).
Last update: Thursday, Sep 6, 2001 16:34:09 PDT
Back to the problem