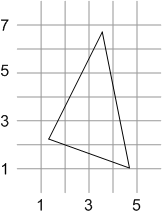
(3, 2); (4, 2); (2, 3); (3, 3); (4, 3); (3, 4); (4, 4); (3, 5).
(I'm using the shadow rule that points directly on a pixel which lie on the right side of a scanline are drawn, but ones on the left side are not.)
I'm asking for your help in solving the following problem. On an architecture which does not allow control-flow branches (if-then), find an efficient algorithm to take a prepped screen-space triangle as an input and, on each loop through the algorithm, output a screen-space pixel location covered by that triangle. The algorithm should run as fast as possible and, while it can output invalid pixels and mark them invalid, it should minimize the number of invalid pixels output.
Interested? Keep reading!
Greetings! My name is John Owens and I have a graphics algorithm problem. This web page is a little long, but I hope it fully describes the problem. The problem is pretty simple. I would like an efficient routine which takes a screen-space triangle, with vertices at arbitrary floating-point values, as input and emits all the integer screen-space grid points covered by that triangle. Here's an example:
|
|
The points covered by this triangle are: (3, 2); (4, 2); (2, 3); (3, 3); (4, 3); (3, 4); (4, 4); (3, 5). (I'm using the shadow rule that points directly on a pixel which lie on the right side of a scanline are drawn, but ones on the left side are not.) |
This procedure is exactly what rasterizers do. However, my problem has some important restrictions that make it difficult (and more interesting!), which I will enumerate below.
In my graphics pipeline, it's the largest single chunk of runtime, and its poor performance in identifying valid pixels leads to further inefficiencies further on in the pipeline. So I am interested in getting a better solution, which is why I'm asking your help.
This isn't a very complete description of the hardware; I've put together a longer description here.
loop over all triangles {
bring in new triangle if we're done with the last one;
compute one pixel which is covered by this triangle;
output that pixel;
output if that pixel is valid (actually covers a pixel in the triangle);
decide if we're done with the current triangle;
}
Another way to write this loop is with the conditional input at the
end of the loop:
loop over all triangles {
compute one pixel which is covered by the current triangle;
output that pixel;
output if that pixel is valid (actually covers a pixel in the triangle);
decide if we're done with the current triangle;
if so, bring in new triangle;
}
I must output a pixel on every loop. The pixel doesn't have to be
valid because each pixel is associated with a valid bit. This comes in
handy in many cases, for example: I input a triangle which is very
small and doesn't overlap any pixels. Because of the way my loop is
structured, I have to output at least one pixel per triangle. There
aren't any valid pixels for that triangle, so instead I output one
pixel and mark it as invalid.
It is not too hard to find algorithms which perform well on one metric but not on the other. For example, traversing the bounding box of each triangle would probably generate a very fast loop because the control complexity is small. But most of the pixels generated would be inside the triangle but outside the bounding box, and would thus be invalid.
The key restriction is that I must go directly from triangles to pixels in this loop, and we only get to visit each triangle once. Once we begin a triangle, we have to output all its pixels, one pixel per loop, until we are done. Then we can't revisit it. It would be more efficient if I were to input triangles and output spans in one loop, and then input spans and output pixels in a second step. That's what most commercial rasterizers do. I can't do that - I have to do it all in one step. Also, it means that algorithms which split the triangle in half to make half-triangles (which lend themselves to simpler control) are much more difficult to do (possible, but lots of overhead, so not worth it in overall runtime). If you want a more satisfying technical explanation, please contact me.
The restriction that we don't have any branches means that in practice, when we have multiple threads of execution, we have to evaluate all of them, and then at the end, select the right one. For example, to bring in a new triangle:
loop {
...
triangle_stream(need_new_triangle) >> new_triangle;
triangle = need_new_triangle ? new_triangle : triangle;
...
}
Note triangle is held as loop-carried state from one iteration of the loop to the next.
It is important to optimize for small triangles. It is tempting to suggest solutions which work better for large triangles, in particular solutions which impose a significant per-triangle cost. (One example is algorithms which pipeline the carrying of loop-carried state to avoid long loop-carried dependencies. However, this means that we always output two or more pixels per triangle, no matter how small the triangle is. I am resigned to doing one pixel for every triangle, valid or not, but don't want to be required to do more than one.)
The current implementation is pretty bad. It makes poor use of the hardware, it is slow, and it does not get good efficiency on valid pixels (about 65-70%).
It essentially uses a scanline method. We keep a triangle as loop-carried state. On each loop we decide if we need a new triangle or not, and bring in a new one if necessary. We also keep track of the current scanline as loop-carried state. We decide if we need to move to the next scanline or not and increment the current scanline if so. Finally, we output the current pixel.
What this means is that we're actually evaluating three different calculations each time through the loop:
Not surprisingly, this isn't efficient. It's pretty control heavy. More information on the current implementation, including source code, can be found here.
I thought this would be a better approach because in the normal case, it's difficult to figure out a good traversal over an irregular triangle. I thought maybe I'd try a regular triangle but an irregular grid. Unfortunately, this didn't work out so well because I couldn't figure out a good algorithm to traverse the irregular grid.
I'm really interested in getting this problem solved (hence the lengthy writeup). If you have questions, please drop me a line (jowens @ graphics.stanford.edu). Also, if anything is unclear here I will happily clarify; I intend to build a FAQ list if I get good questions.
Thanks!