This web page contains links to all my papers back to 1990, and selected ones
beyond that. The list is sorted by topic, and then in reverse chronological
order within each topic. A complete list may be found in my CV. For some of the older papers, PDFs have been
created from optical scans of the original publications. The entries for some
papers include links to software, data, other papers, or historical notes about
the paper. The visualization at right below was created from the words on this
page (with minor editing) using http://www.wordle.net.
|
Computational photography
|
(papers on light fields are farther down on this page)
|
|

|
Removing Reflections from RAW Photos
Eric Kee, Adam Pikielny,
Kevin Blackburn-Matzen,
Marc Levoy,
To appear in
Proc. CVPR 2025.
(preprint available in
arXiv:2404.14414)
This technology was first demoed
at an Adobe MAX
Sneak Peek in October 2023 ("Project SeeThrough").
See also this
Adobe blog.
The technology is available in Adobe Camera Raw, Adobe
Lightroom, and on iPhone in the
Project Indigo camera app.
|
We describe a system to remove real-world reflections from images for consumer
photography. Our system operates on linear (RAW) photos, with the (optional)
addition of a contextual photo looking in the opposite direction, e.g., using the
selfie camera on a mobile device, which helps disambiguate what should be
considered the reflection. The system is trained using synthetic mixtures of
real-world RAW images, which are combined using a reflection simulation that is
photometrically and geometrically accurate. Our system consists of a base model
that accepts the captured photo and optional contextual photo as input, and runs
at 256p, followed by an up-sampling model that transforms output 256p images to
full resolution. The system can produce images for review at 1K in 4.5 to 6.5
seconds on a MacBook or iPhone 14 Pro. We test on RAW photos that were captured
in the field and embody typical consumer photographs.
|
|


|
Handheld Mobile Photography in Very Low Light
Orly Liba, Kiran Murthy, Yun-Ta Tsai, Tim Brooks, Tianfan Xue, Nikhil Karnad,
Qiurui He, Jonathan T. Barron, Dillon Sharlet, Ryan Geiss, Samuel W. Hasinoff,
Yael Pritch,
Marc Levoy,
ACM Transactions on Graphics 38(6)
(Proc. SIGGRAPH Asia 2019)
This paper describes the technology in Night Sight on Google Pixel 3.
Main and supplemental material in a single document here on
Arxiv.
Click here for an
earlier
article
in the Google Research blog.
For Pixel 4 and astrophotography, see this more recent
article.
|
Taking photographs in low light using a mobile phone is challenging and rarely
produces pleasing results. Aside from the physical limits imposed by read noise
and photon shot noise, these cameras are typically handheld, have small
apertures and sensors, use mass-produced analog electronics that cannot easily
be cooled, and are commonly used to photograph subjects that move, like
children and pets. In this paper we describe a system for capturing clean,
sharp, colorful photographs in light as low as 0.3~lux, where human vision
becomes monochromatic and indistinct. To permit handheld photography without
flash illumination, we capture, align, and combine multiple frames. Our system
employs "motion metering", which uses an estimate of motion magnitudes (whether
due to handshake or moving objects) to identify the number of frames and the
per-frame exposure times that together minimize both noise and motion blur in a
captured burst. We combine these frames using robust alignment and merging
techniques that are specialized for high-noise imagery. To ensure accurate
colors in such low light, we employ a learning-based auto white balancing
algorithm. To prevent the photographs from looking like they were shot in
daylight, we use tone mapping techniques inspired by illusionistic painting:
increasing contrast, crushing shadows to black, and surrounding the scene with
darkness. All of these processes are performed using the limited computational
resources of a mobile device. Our system can be used by novice photographers to
produce shareable pictures in a few seconds based on a single shutter press,
even in environments so dim that humans cannot see clearly.
|
|

|
Handheld Multi-Frame Super-Resolution
Bartlomiej Wronski, Ignacio Garcia-Dorado, Manfred Ernst, Damien Kelly,
Michael Krainin, Chia-Kai Liang,
Marc Levoy,
Peyman Milanfar,
ACM Transactions on Graphics,
(Proc. SIGGRAPH 2019)
Click here for an earlier related article in the
Google Research Blog.
See also these interviews by
DP Review (or
video) and
CNET.
|
Compared to DSLR cameras, smartphone cameras have smaller sensors, which limits
their spatial resolution; smaller apertures, which limits their light gathering
ability; and smaller pixels, which reduces their signal-to- noise ratio. The
use of color filter arrays (CFAs) requires demosaicing, which further degrades
resolution. In this paper, we supplant the use of traditional demosaicing in
single-frame and burst photography pipelines with a multi- frame
super-resolution algorithm that creates a complete RGB image directly from a
burst of CFA raw images. We harness natural hand tremor, typical in handheld
photography, to acquire a burst of raw frames with small offsets. These frames
are then aligned and merged to form a single image with red, green, and blue
values at every pixel site. This approach, which includes no explicit
demosaicing step, serves to both increase image resolution and boost signal to
noise ratio. Our algorithm is robust to challenging scene conditions: local
motion, occlusion, or scene changes. It runs at 100 milliseconds per
12-megapixel RAW input burst frame on mass-produced mobile
phones. Specifically, the algorithm is the basis of the Super-Res Zoom feature,
as well as the default merge method in Night Sight mode (whether zooming or
not) on Google’s flagship phone.
|
|

|
Synthetic Depth-of-Field with a Single-Camera Mobile Phone
Neal Wadhwa, Rahul Garg, David E. Jacobs, Bryan E. Feldman, Nori Kanazawa,
Robert Carroll, Yair Movshovitz-Attias, Jonathan T. Barron, Yael Pritch,
Marc Levoy
ACM Transactions on Graphics 37(4),
(Proc. SIGGRAPH 2018)
Click here for an earlier article in the
Google Research Blog.
And here for articles on
learning-based depth
(published in
Proc. ICCV 2019)
and
dual-pixel + dual-camera
(published in
Proc. ECCV 2020).
Click here for an
API for reading
dual-pixels from Pixel phones.
|
Shallow depth-of-field is commonly used by photographers to isolate a subject
from a distracting background. However, standard cell phone cameras cannot
produce such images optically, as their short focal lengths and small apertures
capture nearly all-in-focus images. We present a system to computationally
synthesize shallow depth-of-field images with a single mobile camera and a
single button press. If the image is of a person, we use a person segmentation
network to separate the person and their accessories from the background. If
available, we also use dense dual-pixel auto-focus hardware, effectively a
2-sample light field with an approximately 1 millimeter baseline, to compute a
dense depth map. These two signals are combined and used to render a defocused
image. Our system can process a 5.4 megapixel image in 4 seconds on a mobile
phone, is fully automatic, and is robust enough to be used by non-experts. The
modular nature of our system allows it to degrade naturally in the absence of a
dual-pixel sensor or a human subject.
|
|

|
Portrait mode on the Pixel 2 and Pixel 2 XL smartphones
Marc Levoy,
Yael Pritch
Google Research blog,
October 17, 2017.
Click here for a
feeder article in
Google's blog,
The Keyword.
And here for another blog post, giving
10 tips for using portrait mode.
See also our follow-on
paper in SIGGRAPH 2018.
|
Portrait mode, a major feature of the new Pixel 2 and Pixel 2 XL smartphones,
allows anyone to take professional-looking shallow depth-of-field images. This
feature helped both devices earn
DxO's
highest mobile camera ranking, and works
with both the rear-facing and front-facing cameras, even though neither is
dual-camera (normally required to obtain this effect). [In this article] we
discuss the machine learning and computational photography techniques behind
this feature.
|
|

|
Burst photography for high dynamic range and low-light imaging on mobile cameras,
Samuel W. Hasinoff,
Dillon Sharlet,
Ryan Geiss,
Andrew Adams,
Jonathan T. Barron,
Florian Kainz,
Jiawen Chen,
Marc Levoy
Proc SIGGRAPH Asia 2016.
Click here for
Supplemental material,
and for an
archive of burst photography data
and a
blog about it.
And here for a blog about
Live HDR+,
the real-time, learning-based approximation of HDR+ used to make
Pixel 4's viewfinder WYSIWYG relative to the final HDR+ photo.
And a 2021 blog about adding
bracketing to HDR+.
|
Cell phone cameras have small apertures, which limits the number of photons
they can gather, leading to noisy images in low light. They also have small
sensor pixels, which limits the number of electrons each pixel can store,
leading to limited dynamic range. We describe a computational photography
pipeline that captures, aligns, and merges a burst of frames to reduce noise
and increase dynamic range. Our solution differs from previous HDR systems in
several ways. First, we do not use bracketed exposures. Instead, we capture
frames of constant exposure, which makes alignment more robust, and we set this
exposure low enough to avoid blowing out highlights. The resulting merged image
has clean shadows and high bit depth, allowing us to apply standard HDR tone
mapping methods. Second, we begin from Bayer raw frames rather than the
demosaicked RGB (or YUV) frames produced by hardware Image Signal Processors
(ISPs) common on mobile platforms. This gives us more bits per pixel and allows
us to circumvent the ISP's unwanted tone mapping and spatial denoising. Third,
we use a novel FFT-based alignment algorithm and a hybrid 2D/3D Wiener filter
to denoise and merge the frames in a burst. Our implementation is built atop
Android's Camera2 API, which provides per-frame camera control and access to
raw imagery, and is written in the Halide domain-specific language (DSL). It
runs in 4 seconds on device (for a 12 Mpix image), requires no user
intervention, and ships on several mass-produced cell phones.
|
|

|
Simulating the Visual Experience of Very Bright and Very Dark Scenes,
David E. Jacobs,
Orazio Gallo,
Emily A. Cooper,
Kari Pulli,
Marc Levoy
ACM Transactions on Graphics 34(3),
April 2015.
|
The human visual system can operate in a wide range of illumination levels, due
to several adaptation processes working in concert. For the most part, these
adaptation mechanisms are transparent, leaving the observer unaware of his or
her absolute adaptation state. At extreme illumination levels, however, some of
these mechanisms produce perceivable secondary effects, or epiphenomena. In
bright light, these include bleaching afterimages and adaptation afterimages,
while in dark conditions these include desaturation, loss of acuity, mesopic
hue shift, and the Purkinje effect. In this work we examine whether displaying
these effects explicitly can be used to extend the apparent dynamic range of a
conventional computer display. We present phenomenological models for each
effect, we describe efficient computer graphics methods for rendering our
models, and we propose a gaze-adaptive display that injects the effects into
imagery on a standard computer monitor. Finally, we report the results of
psychophysical experiments, which reveal that while mesopic epiphenomena are a
strong cue that a stimulus is very dark, afterimages have little impact on
perception that a stimulus is very bright.
|
|

|
HDR+: Low Light and High Dynamic Range photography in the Google Camera App
Marc Levoy
Google Research blog,
October 27, 2014.
See also this
SIGGRAPH Asia 2016 paper.
|
As anybody who has tried to use a smartphone to photograph a dimly lit scene
knows, the resulting pictures are often blurry or full of random variations in
brightness from pixel to pixel, known as image noise. Equally frustrating are
smartphone photographs of scenes where there is a large range of brightness
levels, such as a family photo backlit by a bright sky. In high dynamic range
(HDR) situations like this, photographs will either come out with an
overexposed sky (turning it white) or an underexposed family (turning them into
silhouettes). HDR+ is a feature in the Google Camera app for Nexus 5 and Nexus
6 that uses computational photography to help you take better pictures in these
common situations. When you press the shutter button, HDR+ actually captures a
rapid burst of pictures, then quickly combines them into one. This improves
results in both low-light and high dynamic range situations. [In this article]
we delve into each case and describe how HDR+ works to produce a better
picture.
|
|

|
Gyro-Based Multi-Image Deconvolution for Removing Handshake Blur,
Sung Hee Park,
Marc Levoy
Proc. CVPR 2014
Click here for the associated tech report on
handling moving objects and over-exposed regions.
|
Image deblurring to remove blur caused by camera shake has been intensively
studied. Nevertheless, most methods are brittle and computationally
expensive. In this paper we analyze multi-image approaches, which capture and
combine multiple frames in order to make deblurring more robust and
tractable. In particular, we compare the performance of two approaches:
align-and-average and multi-image deconvolution. Our deconvolution is
non-blind, using a blur model obtained from real camera motion as measured by a
gyroscope. We show that in most situations such deconvolution outperforms
align-and-average. We also show, perhaps surprisingly, that deconvolution does
not benefit from increasing exposure time beyond a certain threshold. To
demonstrate the effectiveness and efficiency of our method, we apply it to
still-resolution imagery of natural scenes captured using a mobile camera with
flexible camera control and an attached gyroscope.
|
|

|
WYSIWYG Computational Photography via Viewfinder Editing,
Jongmin Baek,
Dawid Pająk,
Kihwan Kim,
Kari Pulli,
Marc Levoy
ACM Transactions on Graphics
(Proc. SIGGRAPH Asia 2013)
|
Digital cameras with electronic viewfinders provide a relatively faithful
depiction of the final image, providing a WYSIWYG experience. If, however, the
image is created from a burst of differently captured images, or non-linear
interactive edits significantly alter the final outcome, then the photographer
cannot directly see the results, but instead must imagine the post-processing
effects. This paper explores the notion of viewfinder editing, which makes the
viewfinder more accurately reflect the final image the user intends to
create. We allow the user to alter the local or global appearance (tone, color,
saturation, or focus) via stroke-based input, and propagate the edits
spatiotemporally. The system then delivers a real-time visualization of these
modifications to the user, and drives the camera control routines to select
better capture parameters.
|
|
|
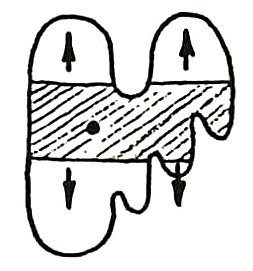
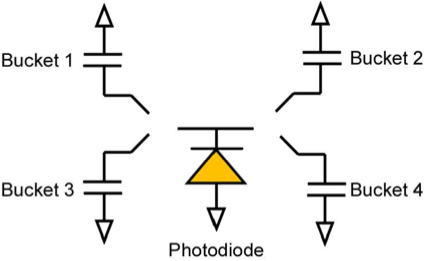
Applications of Multi-Bucket Sensors to Computational Photography,
Gordon Wan,
Mark Horowitz,
Marc Levoy
Stanford Computer Graphics Laboratory Technical Report 2012-2
Later appeared in
IEEE JSSC, Vol. 47, No. 4, April 2012.
|
Many computational photography techniques take the form, "Capture a burst of
images varying camera setting X (exposure, gain, focus, lighting), then align
and combine them to produce a single photograph exhibiting better Y (dynamic
range, signal-to-noise, depth of field). Unfortunately, these techniques may
fail on moving scenes because the images are captured sequentially, so objects
are in different positions in each image, and robust local alignment is
difficult to achieve. To overcome this limitation, we propose using
multi-bucket sensors, which allow the images to be captured in
time-slice-interleaved fashion. This interleaving produces images with nearly
identical positions for moving objects, making alignment unnecessary. To test
our proposal, we have designed and fabricated a 4-bucket, VGA-resolution CMOS
image sensor, and we have applied it to high dynamic range (HDR)
photography. Our sensor permits 4 different exposures to be captured at once
with no motion difference between the exposures. Also, since our protocol
employs non-destructive analog addition of time slices, it requires less total
capture time than capturing a burst of images, thereby reducing total motion
blur. Finally, we apply our multi-bucket sensor to several other computational
photography applications, including flash/no-flash, multi-flash, and flash
matting.
|
|

|
Focal stack compositing for depth of field control,
David E. Jacobs,
Jongmin Baek,
Marc Levoy
Stanford Computer Graphics Laboratory Technical Report 2012-1
|
Many cameras provide insufficient control over depth of field. Some have a
fixed aperture; others have a variable aperture that is either too small or too
large to produce the desired amount of blur. To overcome this limitation, one
can capture a focal stack, which is a collection of images each focused at a
different depth, then combine these slices to form a single composite that
exhibits the desired depth of field. In this paper, we present a theory of
focal stack compositing, and algorithms for computing images with extended
depth of field, shallower depth of field than the lens aperture naturally
provides, or even freeform (non-physical) depth of field. We show that while
these composites are subject to halo artifacts, there is a principled
methodology for avoiding these artifacts - by feathering a slice selection map
according to certain rules before computing the composite image.
|
|

|
Halide: decoupling algorithms from schedules for high performance image processing,
Jonathan Ragan-Kelley,
Andrew Adams,
Connelly Barnes, Dillon Sharlet,
Sylvain Paris,
Marc Levoy,
Saman Amarasinghe,
Fredo Durand
CACM, January 2018, with an introductory
technical perspective by Manuel Chakravarty.
See also original paper in SIGGRAPH 2012 (entry below this one).
|
Writing high-performance code on modern machines requires not just locally
optimizing inner loops, but globally reorganizing compu- tations to exploit
parallelism and locality—doing things like tiling and blocking whole pipelines
to fit in cache. This is especially true for image processing pipelines, where
individual stages do much too little work to amortize the cost of loading and
storing results to and from off-chip memory. As a result, the performance
differ- ence between a naive implementation of a pipeline and one globally
optimized for parallelism and locality is often an order of mag-
nitude. However, using existing programming tools, writing high- performance
image processing code requires sacrificing simplicity, portability, and
modularity. We argue that this is because traditional programming models
conflate what computations define the algo- rithm, with decisions about storage
and the order of computation, which we call the schedule. We propose a new
programming language for image process- ing pipelines, called Halide, that
separates the algorithm from its schedule. Programmers can change the schedule
to express many possible organizations of a single algorithm. The Halide
compiler automatically synthesizes a globally combined loop nest for an en-
tire algorithm, given a schedule. Halide models a space of schedules which is
expressive enough to describe organizations that match or outperform
state-of-the-art hand-written implementations of many computational photography
and computer vision algorithms. Its model is simple enough to do so often in
only a few lines of code, and small changes generate efficient implementations
for x86 and ARM multicores, GPUs, and specialized image processors, all from a
single algorithm. Halide has been public and open source for over four years,
during which it has been used by hundreds of programmers to deploy code to tens
of thousands of servers and hundreds of millions of phones, processing billions
of images every day.
|
|

|
Decoupling algorithms from schedules for easy optimization of image processing pipelines,
Jonathan Ragan-Kelley,
Andrew Adams,
Sylvain Paris,
Marc Levoy,
Saman Amarasinghe,
Fredo Durand
ACM Transactions on Graphics 31(4)
(Proc. SIGGRAPH 2012).
Click here for more information on the
Halide language.
Its compiler is open source and actively supported.
You might also be
interested in our SIGGRAPH 2014 paper on
Darkroom: compiling a Halide-like language into hardware pipelines.
See also reprint in CACM 2018 (entry above this one).
Included in
Seminal Graphics Papers, Volume 2.
|
Using existing programming tools, writing high-performance image processing
code requires sacrificing readability, portability, and modularity. We argue
that this is a consequence of conflating what computations define the
algorithm, with decisions about storage and the order of computation. We refer
to these latter two concerns as the schedule, including choices of tiling,
fusion, recomputation vs. storage, vectorization, and parallelism.
We propose a representation for feed-forward imaging pipelines that separates
the algorithm from its schedule, enabling high-performance without sacrificing
code clarity. This decoupling simplifies the algorithm specification: images
and intermediate buffers become functions over an infinite integer domain, with
no explicit storage or boundary conditions. Imaging pipelines are compositions
of functions. Programmers separately specify scheduling strategies for the
various functions composing the algorithm, which allows them to efficiently
explore different optimizations without changing the algorithmic code.
We demonstrate the power of this representation by expressing a range of recent
image processing applications in an embedded domain specific language called
Halide, and compiling them for ARM, x86, and GPUs. Our compiler targets SIMD
units, multiple cores, and complex memory hierarchies. We demonstrate that it
can handle algorithms such as a camera raw pipeline, the bilateral grid, fast
local Laplacian filtering, and image segmentation. The algorithms expressed in
our language are both shorter and faster than state-of-the-art implementations.
|
|
|
CMOS Image Sensors With Multi-Bucket Pixels for Computational Photography,
Gordon Wan,
Xiangli Li,
Gennadiy Agranov,
Marc Levoy,
Mark Horowitz
IEEE Journal of Solid-State Circuits,
Vol. 47, No. 4, April, 2012, pp. 1031-1042.
|
This paper presents new image sensors with multi-bucket pixels that enable
time-multiplexed exposure, an alternative imaging approach. This approach deals
nicely with scene motion, and greatly improves high dynamic range imaging,
structured light illumination, motion corrected photography, etc. To implement
an in-pixel memory or a bucket, the new image sensors incorporate the virtual
phase CCD concept into a standard 4-transistor CMOS imager pixel. This design
allows us to create a multi-bucket pixel which is compact, scalable, and
supports true correlated double sampling to cancel kTC noise. Two image
sensors with dual and quad-bucket pixels have been designed and fabricated. The
dual-bucket sensor consists of a array of 5.0 m pixel in 0.11 m CMOS technology
while the quad-bucket sensor comprises array of 5.6 m pixel in 0.13 m CMOS
technology. Some computational photography applications were implemented using
the two sensors to demonstrate their values in eliminating artifacts that
currently plague computational photography.
|
|


|
Digital Video Stabilization and Rolling Shutter Correction using Gyroscopes,
Alexandre Karpenko,
David E. Jacobs,
Jongmin Baek,
Marc Levoy
Stanford Computer Science Tech Report CSTR 2011-03,
September, 2011.
Click here for the
source code.
|
In this paper we present a robust, real-time video stabilization and rolling
shutter correction technique based on commodity gyroscopes. First, we develop a
unified algorithm for modeling camera motion and rolling shutter warping. We
then present a novel framework for automatically calibrating the gyroscope and
camera outputs from a single video capture. This calibration allows us to use
only gyroscope data to effectively correct rolling shutter warping and to
stabilize the video. Using our algorithm, we show results for videos featuring
large moving foreground objects, parallax, and low-illumination. We also
compare our method with commercial image-based stabilization algorithms. We
find that our solution is more robust and computationally inexpensive. Finally,
we implement our algorithm directly on a mobile phone. We demonstrate that by
using the phone's inbuilt gyroscope and GPU, we can remove camera shake and
rolling shutter artifacts in real-time.
|
|


|
Experimental Platforms for Computational Photography
Marc Levoy
IEEE Computer Graphics and Applications,
Vol. 30, No. 5, September/October, 2010, pp. 81-87.
If you're looking for our SIGGRAPH 2010 paper on the Frankencamera,
it's the next paper on this web page.
|
Although interest in computational photography has steadily increased among
graphics and vision researchers, few of these techniques have found their way
into commercial cameras. In this article I offer several possible
explanations, including barriers to entry that arise from the current structure
of the photography industry, and an incompleteness and lack of robustness in
current computational photography techniques. To begin addressing these
problems, my laboratory has designed an open architecture for programmable
cameras (called Frankencamera), an API (called FCam) with bindings for C++, and
two reference implementations: a Nokia N900 smartphone with a modified software
stack and a custom camera called the Frankencamera F2. Our short-term goal is
to standardize this architecture and distribute our reference platforms to
researchers and students worldwide. Our long-term goal is to help create an
open-source camera community, leading eventually to commercial cameras that
accept plugins and apps. I discuss the steps that might be needed to bootstrap
this community, including scaling up the world's educational programs in
photographic technology. Finally, I talk about some of future research
challenges in computational photography.
|
|


|
The Frankencamera: An Experimental Platform for Computational Photography
Andrew Adams,
Eino-Ville (Eddy) Talvala,
Sung Hee Park,
David E. Jacobs,
Boris Ajdin,
Natasha Gelfand,
Jennifer Dolson,
Daniel Vaquero,
Jongmin Baek,
Marius Tico,
Henrik P.A. Lensch,
Wojciech Matusik,
Kari Pulli,
Mark Horowitz,
Marc Levoy
Proc. SIGGRAPH 2010.
Reprinted in
CACM, November 2012, with an introductory
technical perspective by Richard Szeliski
If you're looking for our release of the FCam API for the camera on the Nokia
N900 smartphone, click here.
|
Although there has been much interest in computational photography within the
research and photography communities, progress has been hampered by the lack of
a portable, programmable camera with sufficient image quality and computing
power. To address this problem, we have designed and implemented an open
architecture and API for such cameras: the Frankencamera. It consists of a base
hardware specification, a software stack based on Linux, and an API for
C++. Our architecture permits control and synchronization of the sensor and
image processing pipeline at the microsecond time scale, as well as the ability
to incorporate and synchronize external hardware like lenses and flashes. This
paper specifies our architecture and API, and it describes two reference
implementations we have built. Using these implementations we demonstrate six
computational photography applications: HDR viewfinding and capture, low-light
viewfinding and capture, automated acquisition of extended dynamic range
panoramas, foveal imaging, IMU-based hand shake detection, and
rephotography. Our goal is to standardize the architecture and distribute
Frankencameras to researchers and students, as a step towards creating a
community of photographer-programmers who develop algorithms, applications, and
hardware for computational cameras.
|
|
|
Gaussian KD-Trees for Fast High-Dimensional Filtering
Andrew Adams
Natasha Gelfand,
Jennifer Dolson,
Marc Levoy
ACM Transactions on Graphics 28(3),
Proc. SIGGRAPH 2009
A follow-on paper, which filters in high-D using a
permutohedral lattice, was runner-up for best paper
at Eurographics 2010.
|
We propose a method for accelerating a broad class of non-linear filters that
includes the bilateral, non-local means, and other related filters. These
filters can all be expressed in a similar way: First, assign each value to be
filtered a position in some vector space. Then, replace every value with a
weighted linear combination of all val- ues, with weights determined by a
Gaussian function of distance between the positions. If the values are pixel
colors and the posi- tions are (x, y) coordinates, this describes a Gaussian
blur. If the positions are instead (x, y, r, g, b) coordinates in a
five-dimensional space-color volume, this describes a bilateral filter. If we
instead set the positions to local patches of color around the associated
pixel, this describes non-local means. We describe a Monte-Carlo kd- tree
sampling algorithm that efficiently computes any filter that can be expressed
in this way, along with a GPU implementation of this technique. We use this
algorithm to implement an accelerated bilat- eral filter that respects full 3D
color distance; accelerated non-local means on single images, volumes, and
unaligned bursts of images for denoising; and a fast adaptation of non-local
means to geome- try. If we have n values to filter, and each is assigned a
position in a d-dimensional space, then our space complexity is O(dn) and our
time complexity is O(dn log n), whereas existing methods are typically either
exponential in d or quadratic in n.
|
|

|
Spatially Adaptive Photographic Flash
Rolf Adelsberger, Remo Ziegler,
Marc Levoy,
Markus Gross
Technical Report 612, ETH Zurich, Institute of Visual Computing,
December 2008.
|
Using photographic flash for candid shots often results in an unevenly lit
scene, in which objects in the back appear dark. We describe a spatially
adaptive photographic flash system, in which the intensity of illumination
varies depending on the depth and reflectivity of features in the scene. We
adapt to changes in depth using a single-shot method, and to changes in
reflectivity using a multi-shot method. The single-shot method requires only
a depth image, whereas the multi-shot method requires at least one color image
in addition to the depth data. To reduce noise in our depth images, we present
a novel filter that takes into account the amplitude-dependent noise
distribution of observed depth values. To demonstrate our ideas, we have built
a prototype consisting of a depth camera, a flash light, an LCD and a
lens. By attenuating the flash using the LCD, a variety of illumination
effects can be achieved.
|
|

|
Veiling Glare in High Dynamic Range Imaging
Eino-Ville (Eddy)
Talvala,
Andrew Adams,
Mark Horowitz,
Marc Levoy
ACM Transactions on Graphics 26(3),
Proc. SIGGRAPH 2007
|
The ability of a camera to record a high dynamic range image, whether by taking
one snapshot or a sequence, is limited by the presence of veiling glare - the
tendency of bright objects in the scene to reduce the contrast everywhere
within the field of view. Veiling glare is a global illumination effect that
arises from multiple scattering of light inside the camera's optics, body, and
sensor. By measuring separately the direct and indirect components of the
intra-camera light transport, one can increase the maximum dynamic range a
particular camera is capable of recording. In this paper, we quantify the
presence of veiling glare and related optical artifacts for several types of
digital cameras, and we describe two methods for removing them: deconvolution
by a measured glare spread function, and a novel direct-indirect separation of
the lens transport using a structured occlusion mask. By physically blocking
the light that contributes to veiling glare, we attain significantly higher
signal to noise ratios than with deconvolution. Finally, we demonstrate our
separation method for several combinations of cameras and realistic scenes.
|
|

|
Interactive Design of Multi-Perspective Images
for Visualizing Urban Landscapes
Augusto Román,
Gaurav Garg,
Marc Levoy
Proc. Visualization 2004
This project was the genesis of Google's StreetView;
see this
historical note for details.
In a follow-on paper in
EGSR 2006, Augusto Román and Hendrik Lensch describe
an automatic way to compute these multi-perspective panoramas.
|
Multi-perspective images are a useful representation of extended, roughly
planar scenes such as landscapes or city blocks. However, constructing
effective multi-perspective images is something of an art. In this paper, we
describe an interactive system for creating multi-perspective images composed
of serially blended cross-slits mosaics. Beginning with a sideways-looking
video of the scene as might be captured from a moving vehicle, we allow the
user to interactively specify a set of cross-slits cameras, possibly with gaps
between them. In each camera, one of the slits is defined to be the camera
path, which is typically horizontal, and the user is left to choose the second
slit, which is typically vertical. The system then generates intermediate views
between these cameras using a novel interpolation scheme, thereby producing a
multi-perspective image with no seams. The user can also choose the picture
surface in space onto which viewing rays are projected, thereby establishing a
parameterization for the image. We show how the choice of this surface can be
used to create interesting visual effects. We demonstrate our system by
constructing multi-perspective images that summarize city blocks, including
corners, blocks with deep plazas and other challenging urban situations.
|
|
Computational microscopy
|
|
|
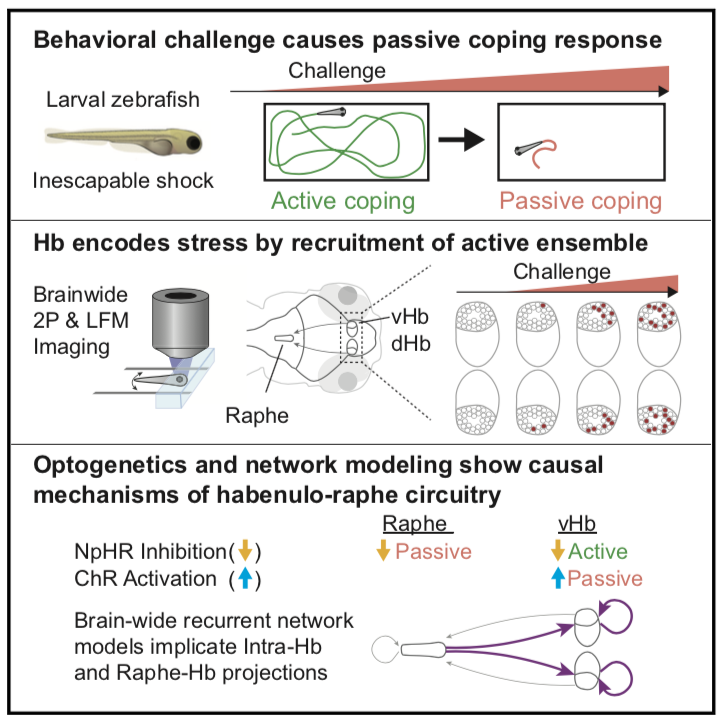
Neuronal Dynamics Regulating Brain and Behavioral State Transitions
Aaron S. Andalman,Vanessa M. Burns, Matthew Lovett-Barron,
Michael Broxton, Ben Poole, Samuel J. Yang, Logan Grosenick,
Talia N. Lerner, Ritchie Chen, Tyler Benster, Philippe Mourrain,
Marc Levoy,
Kanaka Rajan,
Karl Deisseroth
Cell 177, May 2, 2019, pp. 970-985.
https://doi.org/10.1016/j.cell.2019.02.037.
|
Prolonged behavioral challenges can cause animals to switch from active to
passive coping strategies to manage effort-expenditure during stress; such
normally adaptive behavioral state transitions can become maladaptive in
psychiatric disorders such as depression. The underlying neuronal dynamics and
brainwide interactions important for passive coping have remained
unclear. Here, we develop a paradigm to study these behavioral state
transitions at cellular-resolution across the entire vertebrate brain. Using
brainwide imaging in zebrafish, we observed that the transition to passive
coping is manifested by progressive activation of neurons in the ventral
(lateral) habenula. Activation of these ventral-habenula neurons suppressed
downstream neurons in the serotonergic raphe nucleus and caused behavioral
passivity, whereas inhibition of these neurons prevented passivity. Data-driven
recurrent neural network modeling pointed to altered intra-habenula
interactions as a contributory mechanism. These results demonstrate ongoing
encoding of experience features in the habenula, which guides recruitment of
downstream networks and imposes a passive coping behavioral strategy.
|
|

|
Identification of cellular-activity dynamics across large tissue volumes in the
mammalian brain
Logan Grosenick,
Michael Broxton,
Christina K. Kim, Conor Liston,
Ben Poole, Samuel Yang, Aaron Andalman, Edward Scharff, Noy Cohen,
Ofer Yizhar, Charu Ramakrishnan, Surya Ganguli, Patrick Suppes,
Marc Levoy,
Karl Deisseroth
bioRxiv, May 1, 2017,
http://dx.doi.org/10.1101/132688.
|
Tracking the coordinated activity of cellular events through volumes of intact
tissue is a major challenge in biology that has inspired significant
technological innovation. Yet scanless measurement of the high-speed activity
of individual neurons across three dimensions in scattering mammalian tissue
remains an open problem. Here we develop and validate a computational imaging
approach (SWIFT) that integrates high-dimensional, structured statistics with
light field microscopy to allow the synchronous acquisition of single-neuron
resolution activity throughout intact tissue volumes as fast as a camera can
capture images (currently up to 100 Hz at full camera resolution), attaining
rates needed to keep pace with emerging fast calcium and voltage sensors. We
demonstrate that this large field-of-view, single-snapshot volume acquisition
method - -which requires only a simple and inexpensive modification to a
standard fluorescence microscope - -enables scanless capture of coordinated
activity patterns throughout mammalian neural volumes. Further, the volumetric
nature of SWIFT also allows fast in vivo imaging, motion correction, and cell
identification throughout curved subcortical structures like the dorsal
hippocampus, where cellular-resolution dynamics spanning hippocampal subfields
can be simultaneously observed during a virtual context learning task in a
behaving animal. SWIFT’s ability to rapidly and easily record from volumes of
many cells across layers opens the door to widespread identification of
dynamical motifs and timing dependencies among coordinated cell assemblies
during adaptive, modulated, or maladaptive physiological processes in neural
systems.
|
|

|
Enhancing the performance of the light field microscope using wavefront coding
Noy Cohen, Samuel Yang, Aaron Andalman,
Michael Broxton,
Logan Grosenick,
Karl Deisseroth,
Mark Horowitz,
Marc Levoy
Optics Express, Vol. 22, Issue 20 (2014).
|
Light field microscopy has been proposed as a new high-speed volumetric
computational imaging method that enables reconstruction of 3-D volumes from
captured projections of the 4-D light field. Recently, a detailed physical
optics model of the light field microscope has been derived, which led to the
development of a deconvolution algorithm that reconstructs 3-D volumes with
high spatial resolution. However, the spatial resolution of the reconstructions
has been shown to be non-uniform across depth, with some z planes showing high
resolution and others, particularly at the center of the imaged volume, showing
very low resolution. In this paper, we enhance the performance of the light
field microscope using wavefront coding techniques. By including phase masks in
the optical path of the microscope we are able to address this non-uniform
resolution limitation. We have also found that superior control over the
performance of the light field microscope can be achieved by using two phase
masks rather than one, placed at the objective's back focal plane and at the
microscope's native image plane. We present an extended optical model for our
wavefront coded light field microscope and develop a performance metric based
on Fisher information, which we use to choose adequate phase masks
parameters. We validate our approach using both simulated data and experimental
resolution measurements of a USAF 1951 resolution target; and demonstrate the
utility for biological applications with in vivo volumetric calcium imaging of
larval zebrafish brain.
|
|

|
Wave Optics Theory and 3-D Deconvolution for the Light Field Microscope
Michael Broxton,
Logan Grosenick, Samuel Yang, Noy Cohen, Aaron Andalman,
Karl Deisseroth,
Marc Levoy
Optics Express, Vol. 21, Issue 21, pp. 25418-25439 (2013).
|
Light field microscopy is a new technique for high-speed volumetric imaging of
weakly scattering or fluorescent specimens. It employs an array of microlenses
to trade off spatial resolution against angular resolution, thereby allowing a
4-D light field to be captured using a single photographic exposure without the
need for scanning. The recorded light field can then be used to computationally
reconstruct a full volume. In this paper, we present an optical model for light
field microscopy based on wave optics, instead of previously reported ray
optics models. We also present a 3-D deconvolution method for light field
microscopy that is able to reconstruct volumes at higher spatial resolution,
and with better optical sectioning, than previously reported. To accomplish
this, we take advantage of the dense spatio-angular sampling provided by a
microlens array at axial positions away from the native object plane. This
dense sampling permits us to decode aliasing present in the light field to
reconstruct high-frequency information. We formulate our method as an inverse
problem for reconstructing the 3-D volume, which we solve using a
GPU-accelerated iterative algorithm. Theoretical limits on the depth-dependent
lateral resolution of the reconstructed volumes are derived. We show that these
limits are in good agreement with experimental results on a standard USAF 1951
resolution target. Finally, we present 3-D reconstructions of pollen grains
that demonstrate the improvements in fidelity made possible by our method.
|
|

|
Recording and controlling the 4D light field in a microscope
Marc Levoy,
Zhengyun Zhang,
Ian McDowall
Journal of Microscopy, Volume 235, Part 2, 2009, pp. 144-162.
Cover article.
|
By inserting a microlens array at the intermediate image plane of an optical
microscope, one can record 4D light fields of biological specimens in a single
snapshot. Unlike a conventional photograph, light fields permit manipulation
of viewpoint and focus after the snapshot has been taken, subject to the
resolution of the camera and the diffraction limit of the optical system. By
inserting a second microlens array and video projector into the microscope's
illumination path, one can control the incident light field falling on the
specimen in a similar way. In this paper we describe a prototype system we
have built that implements these ideas, and we demonstrate two applications for
it: simulating exotic microscope illumination modalities and correcting for
optical aberrations digitally.
|
|

|
Light Field Microscopy
Marc Levoy,
Ren Ng,
Andrew Adams,
Matthew Footer,
Mark Horowitz
ACM Transactions on Graphics 25(3),
Proc. SIGGRAPH 2006
An additional technical memo containing optical recipes and an
extension to microscopes with infinity-corrected optics.
|
By inserting a microlens array into the optical train of a conventional
microscope, one can capture light fields of biological specimens in a single
photograph. Although diffraction places a limit on the product of spatial and
angular resolution in these light fields, we can nevertheless produce useful
perspective views and focal stacks from them. Since microscopes are inherently
orthographic devices, perspective views represent a new way to look at
microscopic specimens. The ability to create focal stacks from a single
photograph allows moving or light-sensitive specimens to be recorded. Applying
3D deconvolution to these focal stacks, we can produce a set of cross sections,
which can be visualized using volume rendering. In this paper, we demonstrate
a prototype light field microscope (LFM), analyze its optical performance, and
show perspective views, focal stacks, and reconstructed volumes for a variety
of biological specimens. We also show that synthetic focusing followed by 3D
deconvolution is equivalent to applying limited-angle tomography directly to
the 4D light field.
|
|
Light fields
|
(papers on camera arrays are farther down)
|
|

|
Unstructured Light Fields
Abe Davis,
Fredo Durand,
Marc Levoy
Computer Graphics Forum (Proc. Eurographics),
Volume 31, Number 2, 2012.
|
We present a system for interactively acquiring and rendering light fields
using a hand-held commodity camera. The main challenge we address is assisting
a user in achieving good coverage of the 4D domain despite the challenges of
hand-held acquisition. We define coverage by bounding reprojection error
between viewpoints, which accounts for all 4 dimensions of the light field. We
use this criterion together with a recent Simultaneous Localization and
Mapping technique to compute a coverage map on the space of viewpoints. We
provide users with real-time feedback and direct them toward under-sampled
parts of the light field. Our system is lightweight and has allowed us to
capture hundreds of light fields. We further present a new rendering algorithm
that is tailored to the unstructured yet dense data we capture. Our method can
achieve piecewise-bicubic reconstruction using a triangulation of the captured
viewpoints and subdivision rules applied to reconstruction weights.
|
|

|
Wigner Distributions and How They Relate to the Light Field
Zhengyun Zhang,
Marc Levoy
IEEE International Conference on Computational Photography (ICCP) 2009
Best Paper award
|
In wave optics, the Wigner distribution and its Fourier dual, the ambiguity
function, are important tools in optical system simulation and analysis. The
light field fulfills a similar role in the computer graphics community. In this
paper, we establish that the light field as it is used in computer graphics is
equivalent to a smoothed Wigner distribution and that these are equivalent to
the raw Wigner distribution under a geometric optics approximation. Using this
insight, we then explore two recent contributions: Fourier slice photography in
computer graphics and wavefront coding in optics, and we examine the similarity
between explanations of them using Wigner distributions and explanations of
them using light fields. Understanding this long-suspected equivalence may lead
to additional insights and the productive exchange of ideas between the two
fields.
|
|
|
Flexible Multimodal Camera Using a Light Field Architecture
Roarke Horstmeyer, Gary Euliss, Ravindra Athale,
Marc Levoy
IEEE International Conference on Computational Photography (ICCP) 2009
|
We present a modified conventional camera that is able to collect multimodal
images in a single exposure. Utilizing a light field architecture in
conjunction with multiple filters placed in the pupil plane of a main lens, we
are able to digitally reconstruct synthetic images containing specific
spectral, polarimetric, and other optically filtered data. The ease with which
these filters can be exchanged and reconfigured provides a high degree of
flexibility in the type of information that can be collected with each
image. This paper explores the various tradeoffs involved in implementing a
pinhole array in parallel with a pupil-plane filter array to measure
multi-dimensional optical data from a scene. It also examines the design space
of a pupil-plane filter array layout. Images are shown from different
multimodal filter layouts, and techniques to maximize resolution and minimize
error in the synthetic images are proposed.
|
|

|
Combining Confocal Imaging and Descattering
Christian Fuchs, Michael Heinz,
Marc Levoy,
Hendrik P.A. Lensch
Eurographics Symposium on Rendering (EGSR) 2008
|
In translucent objects, light paths are affected by multiple scattering, which
is polluting any observation. Confocal imaging reduces the inï¬uence of such
global illumination effects by carefully focusing illumination and viewing rays
from a large aperture to a speciï¬c location within the object volume. The
selected light paths still contain some global scattering contributions,
though. Descattering based on high frequency illumination serves the same
purpose. It removes the global component from observed light paths. We
demonstrate that confocal imaging and descattering are orthogonal and propose a
novel descattering protocol that analyzes the light transport in a neighborhood
of light transport paths. In combination with confocal imaging, our
descattering method achieves optical sectioning in translucent media with
higher contrast and better resolution.
|
|
|
General Linear Cameras with Finite Aperture
Andrew Adams and
Marc Levoy
Eurographics Symposium on Rendering (EGSR) 2007
|
A pinhole camera selects a two-dimensional set of rays from the
four-dimensional light field. Pinhole cameras are a type of general linear
camera, defined as planar 2D slices of the 4D light field. Cameras with finite
apertures can be considered as the summation of a collection of pinhole
cameras. In the limit they evaluate a two-dimensional integral of the
four-dimensional light field. Hence a general linear camera with finite
aperture factors the 4D light field into two integrated dimensions and two
imaged dimensions. We present a simple framework for representing these slices
and integral projections, based on certain eigenspaces in a two-plane
parameterization of the light field. Our framework allows for easy analysis of
focus and perspective, and it demonstrates their dual nature. Using our
framework, we present analogous taxonomies of perspective and focus, placing
within them the familiar perspective, orthographic, cross-slit, and bilinear
cameras; astigmatic and anastigmatic focus; and several other varieties of
perspective and focus.
|
|

|
Light Fields and Computational Imaging
Marc Levoy
IEEE Computer, August 2006
Includes links to the other four feature articles in that issue,
which was devoted to computational photography
|
A survey of the theory and practice of light field imaging, emphasizing the
devices researchers in computer graphics and computer vision have built to
capture light fields photographically and the techniques they have developed to
compute novel images from them.
|
|

|
Symmetric Photography : Exploiting Data-sparseness in Reflectance Fields
Gaurav Garg,
Eino-Ville (Eddy)
Talvala,
Marc Levoy,
Hendrik P.A. Lensch
Proc. 2006 Eurographics Symposium on Rendering
|
We present a novel technique called symmetric photography to capture real world
reflectance fields. The technique models the 8D reflectance field as a
transport matrix between the 4D incident light field and the 4D exitant light
field. It is a challenging task to acquire this transport matrix due to its
large size. Fortunately, the transport matrix is symmetric and often
data-sparse. Symmetry enables us to measure the light transport from two sides
simultaneously, from the illumination directions and the view
directions. Data-sparseness refers to the fact that sub-blocks of the matrix
can be well approximated using low-rank representations. We introduce the use
of hierarchical tensors as the underlying data structure to capture this
data-sparseness, specifically through local rank-1 factorizations of the
transport matrix. Besides providing an efficient representation for storage, it
enables fast acquisition of the approximated transport matrix and fast
rendering of images from the captured matrix. Our prototype acquisition system
consists of an array of mirrors and a pair of coaxial projector and camera. We
demonstrate the effectiveness of our system with scenes rendered from
reflectance fields that were captured by our system. In these renderings we can
change the viewpoint as well as relight using arbitrary incident light fields.
|
|
|
Dual Photography
Pradeep Sen,
Billy Chen,
Gaurav Garg,
Steve Marschner,
Mark Horowitz,
Marc Levoy,
Hendrik Lensch
ACM Transactions on Graphics 24(3),
Proc. SIGGRAPH 2005
|
We present a novel photographic technique called dual photography, which
exploits Helmholtz reciprocity to interchange the lights and cameras in a
scene. With a video projector providing structured illumination, reciprocity
permits us to generate pictures from the viewpoint of the projector, even
though no camera was present at that location. The technique is completely
image-based, requiring no knowledge of scene geometry or surface properties,
and by its nature automatically includes all transport paths, including
shadows, interreflections and caustics. In its simplest form, the technique can
be used to take photographs without a camera; we demonstrate this by capturing
a photograph using a projector and a photo-resistor. If the photo-resistor is
replaced by a camera, we can produce a 4D dataset that allows for relighting
with 2D incident illumination. Using an array of cameras we can produce a 6D
slice of the 8D reflectance field that allows for relighting with arbitrary
light fields. Since an array of cameras can operate in parallel without
interference, whereas an array of light sources cannot, dual photography is
fundamentally a more efficient way to capture such a 6D dataset than a system
based on multiple projectors and one camera. As an example, we show how dual
photography can be used to capture and relight scenes.
|
|
|
|
Light Field Photography with a Hand-Held Plenoptic Camera
Ren Ng,
Marc Levoy,
Mathieu Brédif, Gene Duval,
Mark Horowitz,
Pat Hanrahan
Stanford University Computer Science Tech Report CSTR 2005-02,
April 2005
The refocusing performance of this camera is analyzed in Ren Ng's SIGGRAPH 2005
paper, Fourier Slice Photography.
Ren's PhD dissertation, "Digital Light Field Photography," won the 2006
ACM Doctoral dissertation Award.
See also his startup company,
Lytro.
|
This paper presents a camera that samples the 4D light field on its sensor in a
single photographic exposure. This is achieved by inserting a microlens array
between the sensor and main lens, creating a plenoptic camera. Each microlens
measures not just the total amount of light deposited at that location, but how
much light arrives along each ray. By re-sorting the measured rays of light to
where they would have terminated in slightly different, synthetic cameras, we
can compute sharp photographs focused at different depths. We show that a
linear increase in the resolution of images under each microlens results in a
linear increase in the sharpness of the refocused photographs. This property
allows us to extend the depth of field of the camera without reducing the
aperture, enabling shorter exposures and lower image noise. Especially in the
macrophotography regime, we demonstrate that we can also compute synthetic
photographs from a range of different viewpoints. These capabilities argue for
a different strategy in designing photographic imaging systems.
To the photographer, the plenoptic camera operates exactly like an ordinary
hand-held camera. We have used our prototype to take hundreds of light field
photographs, and we present examples of portraits, high-speed action and macro
close-ups.
|
|

|
Interactive Deformation of Light Fields
Billy Chen,
Eyal Ofek,
Harry Shum,
Marc Levoy
Proc. Symposium on Interactive 3D Graphics and Games (I3D) 2005
|
We present a software pipeline that enables an animator to deform light fields.
The pipeline can be used to deform complex objects, such as furry toys, while
maintaining photo-realistic quality. Our pipeline consists of three stages.
First, we split the light field into sub-light fields. To facilitate splitting
of complex objects, we employ a novel technique based on projected light
patterns. Second, we deform each sub-light field. To do this, we provide the
animator with controls similar to volumetric free-form deformation. Third, we
recombine and render each sub-light field. Our rendering technique properly
handles visibility changes due to occlusion among sub-light fields. To ensure
consistent illumination of objects after they have been deformed, our light
fields are captured with the light source fixed to the camera, rather than
being fixed to the object. We demonstrate our deformation pipeline using
synthetic and photographically acquired light fields. Potential applications
include animation, interior design, and interactive gaming.
|
|


|
Synthetic aperture confocal imaging
Marc Levoy,
Billy Chen,
Vaibhav Vaish,
Mark Horowitz,
Ian McDowall, Mark Bolas
ACM Transactions on Graphics 23(3),
Proc. SIGGRAPH 2004
About the
relationship between confocal imaging and
separation of direct and global reflections in 3D scenes.
An additional test
of
underwater confocal imaging performed in a large
water tank at the Woods Hole Oceanographic Institution.
|
Confocal microscopy is a family of imaging techniques that employ focused
patterned illumination and synchronized imaging to create cross-sectional views
of 3D biological specimens. In this paper, we adapt confocal imaging to
large-scale scenes by replacing the optical apertures used in microscopy with
arrays of real or virtual video projectors and cameras. Our prototype
implementation uses a video projector, a camera, and an array of mirrors.
Using this implementation, we explore confocal imaging of partially occluded
environments, such as foliage, and weakly scattering environments, such as
murky water. We demonstrate the ability to selectively image any plane in a
partially occluded environment, and to see further through murky water than is
otherwise possible. By thresholding the confocal images, we extract mattes
that can be used to selectively illuminate any plane in the scene.
|
|

|
Light Field Rendering
Marc Levoy and Pat Hanrahan
Proc. SIGGRAPH 1996
About the
similarity between this paper and the Lumigraph paper.
Download our LightPack software.
Or check out our archive of light fields, which includes
the first demonstration of
synthetic aperture focusing
(a.k.a. digital refocusing) of a light field.
Included in
Seminal Graphics Papers, Volume 2.
|
A number of techniques have been proposed for flying through scenes by
redisplaying previously rendered or digitized views. Techniques have also been
proposed for interpolating between views by warping input images, using
depth information or correspondences between multiple images. In this paper,
we describe a simple and robust method for generating new views from arbitrary
camera positions without depth information or feature matching, simply by
combining and resampling the available images. The key to this technique lies
in interpreting the input images as 2D slices of a 4D function - the light
field. This function completely characterizes the flow of light through
unobstructed space in a static scene with fixed illumination.
We describe a sampled representation for light fields that allows for both
efficient creation and display of inward and outward looking views. We have
created light fields from large arrays of both rendered and digitized images.
The latter are acquired using a video camera mounted on a computer-controlled
gantry. Once a light field has been created, new views may be constructed in
real time by extracting slices in appropriate directions. Since the success of
the method depends on having a high sample rate, we describe a compression
system that is able to compress the light fields we have generated by more than
a factor of 100:1 with very little loss of fidelity. We also address the
issues of antialiasing during creation, and resampling during slice extraction.
|
|
Cultural heritage
|
|
|
|
Fragments of the City: Stanford's Digital Forma Urbis Romae Project
David Koller,
Jennifer Trimble, Tina Najbjerg,
Natasha Gelfand,
Marc Levoy
Proc. Third Williams Symposium on Classical Architecture,
Journal of Roman Archaeology supplement,
2006.
Here's a web site about the project.
Or check out our online database of map fragments.
|
In this article, we summarize the Stanford Digital Forma Urbis Project work
since it began in 1999 and discuss its implications for representing and
imaging Rome. First, we digitized the shape and surface of every known fragment
of the Severan Marble Plan using laser range scanners and digital color
cameras; the raw data collected consists of 8 billion polygons and 6 thousand
color images, occupying 40 gigabytes. These range and color data have been
assembled into a set of 3D computer models and high-resolution photographs -
one for each of the 1,186 marble fragments. Second, this data has served in the
development of fragment matching algorithms; to date, these have resulted in
over a dozen highly probable, new matches. Third, we have gathered the
Project's 3D models and color photographs into a relational database and
supported them with archaeological documentation and an up-to-date scholarly
apparatus for each fragment. This database is intended to be a public,
web-based, research and study tool for scholars, students and interested
members of the general public alike; as of this writing, 400 of the surviving
fragments are publicly available, and the full database is scheduled for
release in 2005. Fourth, these digital and archaeological data, and their
availability in a hypertext format, have the potential to broaden the scope and
type of research done on this ancient map by facilitating a range of
typological, representational and urbanistic analyses of the map, some of which
are proposed here. In these several ways, we hope that this Project will
contribute to new ways of imaging Rome.
|
|

|
Computer-aided Reconstruction and New Matches in the Forma Urbis Romae
David Koller
and Marc Levoy
Proc. Formae Urbis Romae - Nuove Scoperte,
Bullettino Della Commissione Archeologica Comunale di Roma,
2006.
See the extra links listed in the next paper up.
|
In this paper, we describe our efforts to apply computer-aided reconstruction
algorithms to find new matches and positionings among the fragments of the
Forma Urbis Romae. First, we review the attributes of the fragments that may be
useful clues for automated reconstruction. Then, we describe several different
specific methods that we have developed which make use of geometric computation
capabilities and digital fragment representations to suggest new matches. These
methods are illustrated with a number of new proposed fragment joins and
placements that have been generated from our computer-aided reconstruction
process.
|
|

|
Unwrapping and Visualizing Cuneiform Tablets
Sean Anderson and Marc Levoy
IEEE Computer Graphics and Applications,
Vol. 22, No. 6, November/December, 2002, pp. 82-88.
|
Thousands of historically revealing cuneiform clay tablets, which were
inscribed in Mesopotamia millenia ago, still exist today. Visualizing
cuneiform writing is important when deciphering what is written on the
tablets. It is also important when reproducing the tablets in papers and
books. Unfortunately, scholars have found photographs to be an inadequate
visualization tool, for two reasons. First, the text wraps around the
sides of some tablets, so a single viewpoint is insufficient. Second, a
raking light will illuminate some textual features, but will leave others
shadowed or invisible because they are either obscured by features on the
tablet or are nearly aligned with the lighting direction. We present
solutions to these problems by first creating a high-resolution 3D computer
model from laser range data, then unwrapping and flattening the inscriptions on
the model to a plane, allowing us to represent them as a scalar displacement
map, and finally, rendering this map non-photorealistically using accessibility
and curvature coloring. The output of this semi-automatic process enables
all of a tablet's text to be perceived in a single concise image. Our
technique can also be applied to other types of inscribed surfaces, including
bas-reliefs.
|
|

|
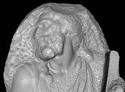
The Digital Michelangelo Project: 3D scanning of large statues,
Marc Levoy, Kari Pulli, Brian Curless, Szymon Rusinkiewicz, David Koller, Lucas Pereira,
Matt Ginzton,
Sean Anderson, James Davis, Jeremy Ginsberg, Jonathan Shade, and Duane Fulk
Proc. SIGGRAPH 2000
Other papers on this project were published in
3DIM '99,
Eurographics '99,
EVA '99,
and as a chapter in the book
Exploring David,
Giunti Press, March 2004.
See also this
web page about the book.
Included in
Seminal Graphics Papers, Volume 2.
Here's a web site about the project.
Download our Scanalyze
or ScanView software.
Or check out our archive of 3D models from the project.
|
We describe a hardware and software system for digitizing the shape and color
of large fragile objects under non-laboratory conditions. Our system employs
laser triangulation rangefinders, laser time-of-flight rangefinders, digital
still cameras, and a suite of software for acquiring, aligning, merging, and
viewing scanned data. As a demonstration of this system, we digitized 10
statues by Michelangelo, including the well-known figure of David, two building
interiors, and all 1,163 extant fragments of the Forma Urbis Romae, a giant
marble map of ancient Rome. Our largest single dataset is of the David - 2
billion polygons and 7,000 color images. In this paper, we discuss the
challenges we faced in building this system, the solutions we employed, and the
lessons we learned. We focus in particular on the unusual design of our laser
triangulation scanner and on the algorithms and software we developed for
handling very large scanned models.
|
|

|
Digitizing the Forma Urbis Romae
Marc Levoy
Siggraph Digital Campfire on Computers and Archeology, April, 2000.
Here's a web site about the project.
Check out our database
of the map fragments.
|
Recent improvements in laser rangefinder technology, together with algorithms
for combining multiple range and color images, allow us to reliably and
accurately digitize the external shape and surface characteristics of many
physical objects. Examples include machine parts, design models, toys, and
artistic and cultural artifacts. As an application of this technology, I and a
team of 30 faculty, staff, and students from Stanford University and the
University of Washington spent the 1998-99 academic year in Italy scanning the
sculptures and architecture of Michelangelo. During our year abroad, we also
became involved in several side projects. One of these was the digitization of
the Forma Urbis Romae...
|
|
Volume rendering and medical imaging
|
|
|
|
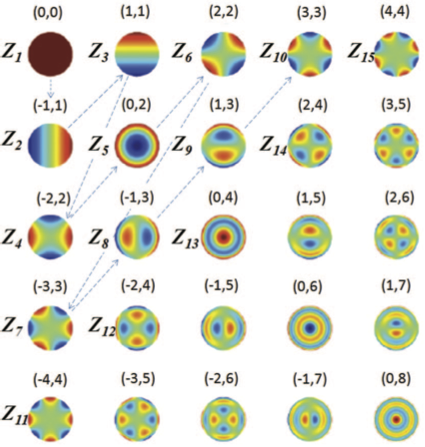
Application of Zernike polynomials towards accelerated adaptive focusing
of transcranial high intensity focused ultrasound,
Elena A. Kaye, Yoni Hertzberg, Michael Marx, Beat Werner, Gil Navon,
Marc Levoy,
and Kim Butts Pauly,
Journal of Medical Physics,
Vol. 39, No. 6254 (2012).
|
Purpose: To study the phase aberrations produced by human skulls during
transcranial magnetic resonance imaging guided focused ultrasound surgery
(MRgFUS), to demonstrate the potential of Zernike polynomials (ZPs) to
accelerate the adaptive focusing process, and to investigate the benefits of
using phase corrections obtained in previous studies to provide the initial
guess for correction of a new data set.
Conclusions: The application of ZPs to phase aberration correction was
shown to be beneficial for adaptive focusing of transcranial ultrasound. The
skull-based phase aberrations were found to be well approximated by the number
of ZP modes representing only a fraction of the number of ele- ments in the
hemispherical transducer. Implementing the initial phase aberration estimate
together with Zernike-based algorithm can be used to improve the robustness and
can potentially greatly increase the viability of MR-ARFI-based focusing for a
clinical transcranial MRgFUS therapy.
|
|
|
Feature-Based Volume Metamorphosis
Apostolos Lerios, Chase D. Garfinkle, and Marc Levoy
Proc. SIGGRAPH 1995
|
Image metamorphosis, or image morphing, is a popular
technique for creating a smooth transition between two images. For
synthetic images, transforming and rendering the underlying
three-dimensional (3D) models has a number of advantages over morphing
between two pre-rendered images. In this paper we consider 3D
metamorphosis applied to volume-based representations of objects. We
discuss the issues which arise in volume morphing and present a method
for creating morphs.
Our morphing method has two components: first a warping of the two
input volumes, then a blending of the resulting warped volumes. The
warping component, an extension of Beier and Neely's image warping
technique to 3D, is feature-based and allows fine user control, thus
ensuring realistic looking intermediate objects. In addition, our
warping method is amenable to an efficient approximation which gives a
50 times speedup and is computable to arbitrary accuracy. Also, our
technique corrects the ghosting problem present in Beier and Neely's
technique. The second component of the morphing process, blending, is
also under user control; this guarantees smooth transitions in the
renderings.
|
|
|
Fast Volume Rendering Using a Shear-Warp Factorization of the Viewing Transformation
Philippe Lacroute and Marc Levoy
Proc. SIGGRAPH 1994
Download the VolPack library.
Or check out our archive of volume data.
|
Several existing volume rendering algorithms operate by factoring the viewing
transformation into a 3D shear parallel to the data slices, a projection to
form an intermediate but distorted image, and a 2D warp to form an undistorted
final image. We extend this class of algorithms in three ways. First, we
describe a new object-order rendering algorithm based on the factorization that
is significantly faster than published algorithms without loss of image
quality. The algorithm achieves its speed by exploiting coherence in the volume
data and the intermediate image. The shear-warp factorization permits us to
traverse both the volume and the intermediate image data structures in
synchrony during rendering, using both types of coherence to reduce work. Our
implementation running on an SGI Indigo workstation renders a 256^3 voxel
medical data set in one second. Our second extension is a derivation of the
factorization for perspective viewing transformations, and we show how our
rendering algorithm can support this extension. Third, we introduce a data
structure for encoding spatial coherence in unclassified volumes (i.e. scalar
fields with no precomputed opacity). When combined with our shear-warp
rendering algorithm this data structure allows us to classify and render a
256^3 voxel volume in three seconds. Our algorithms employ run-length
encoding, min-max pyramids, and multi-dimensional summed area tables. The
method extends readily to support mixed volumes and geometry.
|
|

|
Frequency Domain Volume Rendering
Takashi Totsuka and Marc Levoy
Proc. SIGGRAPH 1993
|
The Fourier projection-slice theorem allows projections of volume data to be
generated in O(n^2 log n) time for a volume of size n^3. The method operates
by extracting and inverse Fourier transforming 2D slices from a 3D frequency
domain representation of the volume. Unfortunately, these projections do not
exhibit the occlusion that is characteristic of conventional volume renderings.
We present a new frequency domain volume rendering algorithm that replaces much
of the missing depth and shape cues by performing shading calculations in the
frequency domain during slice extraction. In particular, we demonstrate
frequency domain methods for computing linear or nonlinear depth cueing and
directional diffuse reflection. The resulting images can be generated an order
of magnitude faster than volume renderings and may be more useful for many
applications.
|
|
|
Volume Rendering using the Fourier Projection-Slice Theorem
Marc Levoy
Proc. Graphics Interface 1992
|
The Fourier projection-slice theorem states that the inverse transform of a
slice extracted from the frequency domain representation of a volume yields a
projection of the volume in a direction perpendicular to the slice. This
theorem allows the generation of attenuation-only renderings of volume data in
O(n^2 log N) time for a volume of size n^3. In this paper, we show how more
realistic renderings can be generated using a class of shading models whose
terms are Fourier projections. Models are derived for rendering depth cueing
by linear attenuation of variable energy emitters and for rendering directional
shading by Lambertian reflection with hemispherical illumination. While the
resulting images do not exhibit the occlusion that is characteristic of
conventional volume rendering, they provide sufficient depth and shape cues to
give a strong illusion that occlusion exists.
|
|

|
A Hybrid Ray Tracer for Rendering Polygon and Volume Data
Marc Levoy
IEEE Computer Graphics and Applications, Vol. 10, No. 2, March, 1990, pp. 33-40.
|
Volume rendering is a technique for visualizing sampled functions of three
spatial dimensions by computing 2D projections of a colored semi-transparent
volume. This paper addresses the problem of extending volume rendering to
handle polygonally defined objects. The solution proposed is a hybrid ray
tracing algorithm. Rays are simultaneously cast through a set of polygons and
a volume data array, samples of each are drawn at equally spaced intervals
along the rays, and the resulting colors and opacities are composited together
in depth-sorted order. To avoid aliasing of polygonal edges at modest
computational expense, a form of selective supersampling is employed. To avoid
errors in visibility at polygon-volume intersections, volume samples lying
immediately in front of and behind polygons are given special treatment. The
cost, image quality, and versatility of the algorithm are evaluated using data
from 3D medical imaging applications.
|
|
|
Volume Rendering by Adaptive Refinement
Marc Levoy
The Visual Computer, Vol. 6, No. 1, February, 1990, pp. 2-7.
|
Volume rendering is a technique for visualizing sampled scalar functions of
three spatial dimensions by computing 2D projections of a colored
semi-transparent gel. This paper presents a volume rendering algorithm in
which image quality is adaptively refined over time. An initial image is
generated by casting a small number of rays into the data, less than one ray
per pixel, and interpolating between the resulting colors. Subsequent images
are generated by alternately casting more rays and interpolating. The
usefulness of these rays is maximized by distributing them according to
measures of local image complexity. Examples from two applications are given:
molecular graphics and medical imaging.
|
|
|
Efficient Ray Tracing of Volume Data
Marc Levoy
ACM Transactions on Graphics, Vol. 9, No. 3, July, 1990, pp. 245-261.
|
Volume rendering is a family of techniques for visualizing sampled scalar or
vector fields of three spatial dimensions without fitting geometric primitives
to the data. A subset of these techniques generate images by computing 2D
projections of a colored semi-transparent volume, where the color and opacity
at each point is derived from the data using local operators. Since all voxels
participate in the generation of each image, rendering time grows linearly with
the size of the dataset. This paper presents a front-to-back image-order volume
rendering algorithm and discusses two techniques for improving its
performance. The first technique employs a pyramid of binary volumes to encode
spatial coherence present in the data, and the second technique uses an opacity
threshold to adaptively terminate ray tracing. Although the actual time saved
depends on the data, speedups of an order of magnitude have been observed for
datasets of useful size and complexity. Examples from two applications are
given: medical imaging and molecular graphics.
|
|
|
Volume Rendering in Radiation Treatment Planning
Marc Levoy, Henry Fuchs, Stephen M. Pizer, Julian Rosenman,
Edward L. Chaney, George W. Sherouse, Victoria Interrante, and Jeffrey Kiel
First Conference on Visualization in Biomedical Computing, IEEE, May, 1990
|
Successful treatment planning in radiation therapy depends in part on
understanding the spatial relationship between patient anatomy and the
distribution of radiation dose. We present several visualizations based on
volume rendering that offer potential solutions to this problem. The
visualizations employ region boundary surfaces to display anatomy, polygonal
meshes to display treatment beams, and isovalue contour surfaces to display
dose. To improve perception of spatial relationships, we use metallic shading,
surface and solid texturing, synthetic fog, shadows, and other artistic
devices. Also outlined is a method based on 3D mip maps for efficiently
generating perspective volume renderings and beam's-eye views. To evaluate the
efficacy of these visualizations, we are building a radiotherapy planning
system based on a Cray YMP and the Pixel-Planes 5 raster display engine. The
system will allow interactive manipulation of beam geometry, dosimetry,
shading, and viewing parameters, and will generate volume renderings of anatomy
and dose in real time.
|
|
|
Display of Surfaces from Volume Data
Marc Levoy
PhD Dissertation,
Tech Report TR89-022,
University of North Carolina at Chapel Hill,
May, 1989.
|
Volume rendering
is a technique for visualizing sampled scalar fields of three spatial
dimensions without fitting geometric primitives to the data. A color and a
partial transparency are computed for each data sample, and images are formed
by blending together contributions made by samples projecting to the same pixel
on the picture plane. Quantization and aliasing artifacts are reduced by
avoiding thresholding during data classification and by carefully resampling
the data during projection. This thesis presents an image-order volume
rendering algorithm, demonstrates that it generates images of comparable
quality to existing object-order algorithms, and offers several improvements.
In particular, methods are presented for displaying isovalue contour surfaces
and region boundary surfaces, for rendering mixtures of analytically defined
geometry and sampled fields, and for adding shadows and textures. Three
techniques for reducing rendering cost are also presented: hierarchical spatial
enumeration, adaptive termination of ray tracing, and adaptive image sampling.
Case studies from two applications are given: medical imaging and molecular
graphics.
|
|
|
Display of Surfaces from Volume Data
Marc Levoy
IEEE Computer Graphics and Applications, Vol. 8, No. 3, May, 1988
About the
error in this paper.
Received the
Test of Time Award
from IEEE CG&A in December 2022.
|
The application of volume rendering techniques to the display of surfaces from
sampled scalar functions of three spatial dimensions is explored. Fitting of
geometric primitives to the sampled data is not required. Images are formed by
directly shading each sample and projecting it onto the picture plane. Surface
shading calculations are performed at every voxel with local gradient vectors
serving as surface normals. In a separate step, surface classification
operators are applied to obtain a partial opacity for every voxel. Operators
that detect isovalue contour surfaces and region boundary surfaces are
presented. Independence of shading and classification calculations insures an
undistorted visualization of 3-D shape. Non-binary classification operators
insure that small or poorly defined features are not lost. The resulting
colors and opacities are composited from back to front along viewing rays to
form an image. The technique is simple and fast, yet displays surfaces
exhibiting smooth silhouettes and few other aliasing artifacts. The use of
selective blurring and super-sampling to further improve image quality is also
described. Examples from two applications are given: molecular graphics and
medical imaging.
|